

集合
发布于2021-04-18 10:01 阅读(1049) 评论(0) 点赞(15) 收藏(0)
集合
-为了保存数量不确定的数据,以及保存具有映射关系的数据(也被称为关联数组),Java 提供了集合类。**集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类。**Java 所有的集合类都位于 java.util 包下,提供了一个表示和操作对象集合的统一构架,包含大量集合接口,以及这些接口的实现类和操作它们的算法。
-区别:集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量),而集合里只能保存对象(实际上只是保存对象的引用变量)。
**Java 集合类型分为 Collection 和 Map,它们是 Java 集合的根接口,**这两个接口又包含了一些子接口或实现类。
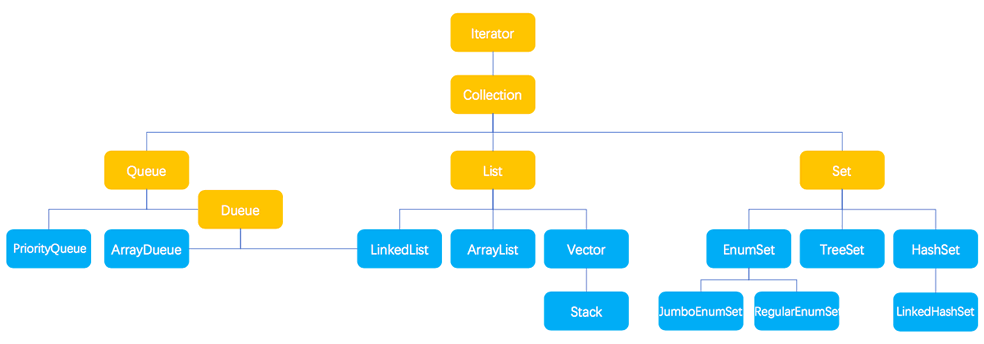
图1 Collection接口基本结构
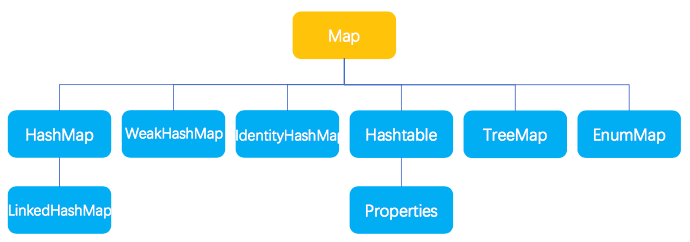
图 2 Map接口基本结构
**Collection 接口是 List、Set 和 Queue 接口的父接口,通常情况下不被直接使用。**Collection 接口定义了一些通用的方法,通过这些方法可以实现对集合的基本操作。定义的方法既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
例1:使用 Collection 接口向集合中添加方法:
public static void main(String[] args) {
ArrayList list1 = new ArrayList(); // 创建集合 list1
ArrayList list2 = new ArrayList(); // 创建集合 list2
list1.add("one"); // 向 list1 添加一个元素
list1.add("two"); // 向 list1 添加一个元素
list2.addAll(list1); // 将 list1 的所有元素添加到 list2
list2.add("three"); // 向 list2 添加一个元素
System.out.println("list2 集合中的元素如下:");
Iterator it1 = list2.iterator();
while (it1.hasNext()) {
System.out.print(it1.next() + "、");
}
}
-Java 所有的集合类都位于 java.util 包下,提供了一个表示和操作对象集合的统一构架,包含大量集合接口,以及这些接口的实现类和操作它们的算法。Java 集合类型分为 Collection 和 Map
-Collection 接口是 List、Set 和 Queue 接口的父接口,通常情况下不被直接使用。
List类
是一个有序、可重复的集合,集合中每个元素都有其对应的顺序索引。**List 集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。**List 集合默认按元素的添加顺序设置元素的索引,第一个添加到 List 集合中的元素的索引为 0,第二个为 1,依此类推。
List 实现了 Collection 接口,它主要有两个常用的实现类:ArrayList 类和 LinkedList 类。
ArrayList类
**ArrayList 类实现了可变数组的大小,存储在内的数据称为元素。**它还提供了快速基于索引访问元素的方式,对尾部成员的增加和删除支持较好。使用 ArrayList 创建的集合,允许对集合中的元素进行快速的随机访问,不过,向 ArrayList 中插入与删除元素的速度相对较慢。
ArrayList 类的常用构造方法有如下两种重载形式:
- ArrayList():构造一个初始容量为 10 的空列表。
- ArrayList(Collection<?extends E>c):构造一个包含指定 Collection 元素的列表,这些元素是按照该 Collection 的迭代器返回它们的顺序排列的。
例1: indexOf() 方法和 lastIndexOf() 方法的区别
public static void main(String[] args) {
List list = new ArrayList();
list.add("One");
list.add("|");
list.add("Two");
list.add("|");
list.add("Three");
list.add("|");
list.add("Four");
System.out.println("list 集合中的元素数量:" + list.size());
System.out.println("list 集合中的元素如下:");
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + "、");
}
System.out.println("\n在 list 集合中'丨'第一次出现的位置是:" + list.indexOf("|"));
System.out.println("在 list 集合中'丨'最后一次出现的位置是:" + list.lastIndexOf("|"));
}
例2:subList() 方法的具体用法
public static void main(String[] args) {
List list = new ArrayList();
list.add("One");
list.add("Two");
list.add("Three");
list.add("Four");
list.add("Five");
list.add("Six");
list.add("Seven");
System.out.println("list 集合中的元素数量:" + list.size());
System.out.println("list 集合中的元素如下:");
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + "、");
}
List sublist = new ArrayList();
sublist = list.subList(2, 5); // 从list集合中截取索引2~5的元素,保存到sublist集合中
System.out.println("\nsublist 集合中元素数量:" + sublist.size());
System.out.println("sublist 集合中的元素如下:");
it = sublist.iterator();
while (it.hasNext()) {
System.out.print(it.next() + "、");
}
}
LinkedList类
LinkedList 类采用链表结构保存对象,这种结构的优点是便于向集合中插入或者删除元素。需要频繁向集合中插入和删除元素时,使用 LinkedList 类比 ArrayList 类效果高,但是 LinkedList 类随机访问元素的速度则相对较慢。
例1:在仓库管理系统中要记录入库的商品名称,并且需要输出第一个录入的商品名称和最后—个商品名称:
public class Test {
public static void main(String[] args) {
LinkedList<String> products = new LinkedList<String>(); // 创建集合对象
String p1 = new String("六角螺母");
String p2 = new String("10A 电缆线");
String p3 = new String("5M 卷尺");
String p4 = new String("4CM 原木方板");
products.add(p1); // 将 p1 对象添加到 LinkedList 集合中
products.add(p2); // 将 p2 对象添加到 LinkedList 集合中
products.add(p3); // 将 p3 对象添加到 LinkedList 集合中
products.add(p4); // 将 p4 对象添加到 LinkedList 集合中
String p5 = new String("标准文件夹小柜");
products.addLast(p5); // 向集合的末尾添加p5对象
System.out.print("*************** 商品信息 ***************");
System.out.println("\n目前商品有:");
for (int i = 0; i < products.size(); i++) {
System.out.print(products.get(i) + "\t");
}
System.out.println("\n第一个商品的名称为:" + products.getFirst());
System.out.println("最后一个商品的名称为:" + products.getLast());
products.removeLast(); // 删除最后一个元素
System.out.println("删除最后的元素,目前商品有:");
for (int i = 0; i < products.size(); i++) {
System.out.print(products.get(i) + "\t");
}
}
}
注:LinkedList 中的 是 Java 中的泛型,用于指定集合中元素的数据类型,例如这里指定元素类型为 String,则该集合中不能添加非 String 类型的元素。
ArrayList 类和 LinkedList 类的区别
ArrayList 与 LinkedList 都是 List 接口的实现类,因此都实现了 List 的所有未实现的方法,只是实现的方式有所不同。
ArrayList 是基于动态数组数据结构的实现,访问元素速度优于 LinkedList。LinkedList 是基于链表数据结构的实现,占用的内存空间比较大,但在批量插入或删除数据时优于 ArrayList。
对于快速访问对象的需求,使用 ArrayList 实现执行效率上会比较好。需要频繁向集合中插入和删除元素时,使用 LinkedList 类比 ArrayList 类效果高。
Set类
Set 集合类似于一个罐子,程序可以依次把多个对象“丢进”Set 集合,而 **Set 集合通常不能记住元素的添加顺序。**也就是说 Set 集合中的对象不按特定的方式排序,只是简单地把对象加入集合。Set 集合中不能包含重复的对象,并且最多只允许包含一个 null 元素。
Set 实现了 Collection 接口,它主要有两个常用的实现类:HashSet 类和 TreeSet类。
HashSet 类
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时就是使用这个实现类。HashSet 是按照 Hash 算法来存储集合中的元素。因此具有很好的存取和查找性能。
HashSet 具有以下特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
- HashSet 不是同步的,如果多个线程同时访问或修改一个 HashSet,则必须通过代码来保证其同步。
- 集合元素值可以是 null。
当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据该 hashCode 值决定该对象在 HashSet 中的存储位置。如果有两个元素通过 equals() 方法比较返回的结果为 true,但它们的 hashCode 不相等,HashSet 将会把它们存储在不同的位置,依然可以添加成功。
也就是说,两个对象的 hashCode 值相等且通过 equals() 方法比较返回结果为 true,则 HashSet 集合认为两个元素相等。
在 HashSet 类中实现了 Collection 接口中的所有方法。HashSet 类的常用构造方法重载形式如下。
- HashSet():构造一个新的空的 Set 集合。
- HashSet(Collection<? extends E>c):构造一个包含指定 Collection 集合元素的新 Set 集合。其中,“< >”中的 extends 表示 HashSet 的父类,即指明该 Set 集合中存放的集合元素类型。c 表示其中的元素将被存放在此 Set 集合中。
创建两种不同形式的 HashSet 对象:
HashSet hs = new HashSet(); // 调用无参的构造函数创建HashSet对象
HashSet<String> hss = new HashSet<String>(); // 创建泛型的 HashSet 集合对象
例1:使用 HashSet 创建一个 Set 集合,并向该集合中添加 4 套教程。
public static void main(String[] args) {
HashSet<String> courseSet = new HashSet<String>(); // 创建一个空的 Set 集合
String course1 = new String("Java入门教程");
String course2 = new String("Python基础教程");
String course3 = new String("C语言学习教程");
String course4 = new String("Golang入门教程");
courseSet.add(course1); // 将 course1 存储到 Set 集合中
courseSet.add(course2); // 将 course2 存储到 Set 集合中
courseSet.add(course3); // 将 course3 存储到 Set 集合中
courseSet.add(course4); // 将 course4 存储到 Set 集合中
System.out.println("C语:");
Iterator<String> it = courseSet.iterator();
while (it.hasNext()) {
System.out.println("《" + (String) it.next() + "》"); // 输出 Set 集合中的元素
}
System.out.println("有" + courseSet.size() + "O");
}
如果向 Set 集合中添加两个相同的元素,则后添加的会覆盖前面添加的元素,即在 Set 集合中不会出现相同的元素。
TreeSet 类
**TreeSet 类同时实现了 Set 接口和 SortedSet 接口。**SortedSet 接口是 Set 接口的子接口,可以实现对集合进行自然排序,因此使用 TreeSet 类实现的 Set 接口默认情况下是自然排序。
**TreeSet 只能对实现了 Comparable 接口的类对象进行排序,因为 Comparable 接口中有一个 compareTo(Object o) 方法用于比较两个对象的大小。**例如 a.compareTo(b),如果 a 和 b 相等,则该方法返回 0;如果 a 大于 b,则该方法返回大于 0 的值;如果 a 小于 b,则该方法返回小于 0 的值。
例1:使用 TreeSet 类来创建 Set 集合,完成学生成绩查询功能
public class Test08 {
public static void main(String[] args) {
TreeSet<Double> scores = new TreeSet<Double>(); // 创建 TreeSet 集合
Scanner input = new Scanner(System.in);
System.out.println("------------学生成绩管理系统-------------");
for (int i = 0; i < 5; i++) {
System.out.println("第" + (i + 1) + "个学生成绩:");
double score = input.nextDouble();
// 将学生成绩转换为Double类型,添加到TreeSet集合中
scores.add(Double.valueOf(score));
}
Iterator<Double> it = scores.iterator(); // 创建 Iterator 对象
System.out.println("学生成绩从低到高的排序为:");
while (it.hasNext()) {
System.out.print(it.next() + "\t");
}
System.out.println("\n请输入要查询的成绩:");
double searchScore = input.nextDouble();
if (scores.contains(searchScore)) {
System.out.println("成绩为: " + searchScore + " 的学生存在!");
} else {
System.out.println("成绩为: " + searchScore + " 的学生不存在!");
}
// 查询不及格的学生成绩
SortedSet<Double> score1 = scores.headSet(60.0);
System.out.println("\n不及格的成绩有:");
for (int i = 0; i < score1.toArray().length; i++) {
System.out.print(score1.toArray()[i] + "\t");
}
// 查询90分以上的学生成绩
SortedSet<Double> score2 = scores.tailSet(90.0);
System.out.println("\n90 分以上的成绩有:");
for (int i = 0; i < score2.toArray().length; i++) {
System.out.print(score2.toArray()[i] + "\t");
}
}
}
在使用自然排序时只能向 TreeSet 集合中添加相同数据类型的对象,否则会抛出 ClassCastException 异常。如果向 TreeSet 集合中添加了一个 Double 类型的对象,则后面只能添加 Double 对象,不能再添加其他类型的对象,例如 String 对象等。
Map
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键(key)对象和一个值(value)对象。用于保存具有映射关系的数据。
Map 集合里保存着两组值,一组值用于保存 Map 里的 key,另外一组值用于保存 Map 里的 value,key 和 value 都可以是任何引用类型的数据。Map 的 key 不允许重复,value 可以重复,即同一个 Map 对象的任何两个 key 通过 equals 方法比较总是返回 false。
Map 中的 key 和 value 之间存在单向一对一关系,即通过指定的 key,总能找到唯一的、确定的 value。从 Map 中取出数据时,只要给出指定的 key,就可以取出对应的 value。
**Map 接口主要有两个实现类:HashMap 类和 TreeMap 类。**其中,HashMap 类按哈希算法来存取键对象,而 TreeMap 类可以对键对象进行排序。
例1:使用 HashMap 来存储学生信息,其键为学生学号,值为姓名。毕业时,需要用户输入学生的学号,并根据学号进行删除操作。具体的实现代码如下:
public class Test09 {
public static void main(String[] args) {
HashMap users = new HashMap();
users.put("11", "张浩太"); // 将学生信息键值对存储到Map中
users.put("22", "刘思诚");
users.put("33", "王强文");
users.put("44", "李国量");
users.put("55", "王路路");
System.out.println("******** 学生列表 ********");
Iterator it = users.keySet().iterator();
while (it.hasNext()) {
// 遍历 Map
Object key = it.next();
Object val = users.get(key);
System.out.println("学号:" + key + ",姓名:" + val);
}
Scanner input = new Scanner(System.in);
System.out.println("请输入要删除的学号:");
int num = input.nextInt();
if (users.containsKey(String.valueOf(num))) { // 判断是否包含指定键
users.remove(String.valueOf(num)); // 如果包含就删除
} else {
System.out.println("该学生不存在!");
}
System.out.println("******** 学生列表 ********");
it = users.keySet().iterator();
while (it.hasNext()) {
Object key = it.next();
Object val = users.get(key);
System.out.println("学号:" + key + ",姓名:" + val);
}
}
}
注:TreeMap 类的使用方法与 HashMap 类相同,唯一不同的是 TreeMap 类可以对键对象进行排序
Map 集合的遍历与 List 和 Set 集合不同。Map 有两组值,因此遍历时可以只遍历值的集合,也可以只遍历键的集合,也可以同时遍历。Map 以及实现 Map 的接口类(如 HashMap、TreeMap、LinkedHashMap、Hashtable 等)都可以用以下几种方式遍历
1)在 for 循环中使用 entries 实现 Map 的遍历(最常见和最常用的)。
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("好好学习,天天向上");
map.put("滴滴滴”);
for (Map.Entry<String, String> entry : map.entrySet()) {
String mapKey = entry.getKey();
String mapValue = entry.getValue();
System.out.println(mapKey + ":" + mapValue);
}
}
2)使用 for-each 循环遍历 key 或者 values,一般适用于只需要 Map 中的 key 或者 value 时使用。性能上比 entrySet 较好。
Map<String, String> map = new HashMap<String, String>();
map.put("滴滴滴");
map.put("嗒嗒嗒");
// 打印键集合
for (String key : map.keySet()) {
System.out.println(key);
}
// 打印值集合
for (String value : map.values()) {
System.out.println(value);
}
3)使用迭代器(Iterator)遍历
Map<String, String> map = new HashMap<String, String>();
map.put("精神科萨");
map.put("为截断符in类似款式的呢");
Iterator<Entry<String, String>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Entry<String, String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
4)通过键找值遍历,这种方式的效率比较低,因为本身从键取值是耗时的操作。
for(String key : map.keySet()){
String value = map.get(key);
System.out.println(key+":"+value);
}
泛型集合
泛型可以在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高了代码的重用率
**泛型本质上是提供类型的“类型参数”,也就是参数化类型。**我们可以为类、接口或方法指定一个类型参数,通过这个参数限制操作的数据类型,从而保证类型转换的绝对安全。
泛型类
除了可以定义泛型集合之外,还可以直接限定泛型类的类型参数。语法格式如下:
public class class_name<data_type1,data_type2,…>{}
其中,class_name 表示类的名称,data_ type1 等表示类型参数。Java 泛型支持声明一个以上的类型参数,只需要将类型用逗号隔开即可。
泛型类一般用于类中的属性类型不确定的情况下。在声明属性时,使用下面的语句:
private data_type1 property_name1;
private data_type2 property_name2;
该语句中的 data_type1 与类声明中的 data_type1 表示的是同一种数据类型。
在实例化泛型类时,需要指明泛型类中的类型参数,并赋予泛型类属性相应类型的值。
HashMap底层原理
hashmap是数组和链表组成的,数据结构中又叫“链表散列”。
hashmap特点:
- 快速存储 :比如当我们对hashmap进行get和put的时候速度非常快
- 快速查找(时间复杂度o(1))当我们通过key去get一个value的时候时间复杂度非常的低,效率非常高
- 可伸缩:1数组扩容,边长。2,单线列表如果长度超过8的话会变成红黑树
Hash值的计算
Hash值=(hashcode)^(hashcode >>> 16)
Hashcode予hashcode自己向右位移16位的异或运算。这样可以确保算出来的值足够随机。
因为进行hash计算的时候足够分散,以便于计算数组下标的时候算的值足够分散。
hashmap的底层是由数组组成,数组默认大小是16,那么数组下标是怎么计算出来的呢,那就是:
数组下标:hash&(16-1) = hash%16
对哈希计算得到的hash进行16的求余,得到一个16的位数,比如说是1到15之间的一个数,hashmap会与hash值和15进行予运算。
这样可以效率会更高。计算机中会容易识别这种向右位移,向左位移。
Hashmap的扩容并不是为单线链表准备的,单线链表只是为了解决hash冲突准备的。
也就是说当数组达到一定长度,比如说hashmap默认数组长度是16,
那么达到出发条件,数组存储比例达到了75% ,也就是16*0.75=12的时候就会发生扩容
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认初始化大小 16
static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子0.75
static final Entry<?,?>[] EMPTY_TABLE = {}; //初始化的默认数组
transient int size; //HashMap中元素的数量
int threshold; //判断是否需要调整HashMap的容量
异常
异常(exception)是在运行程序时产生的一种异常情况
在 Java 中所有异常类型都是内置类 java.lang.Throwable 类的子类,即 Throwable 位于异常类层次结构的顶层。
Throwable 类下有两个异常分支 Exception 和 Error,Throwable 类是所有异常和错误的超类,下面有 Error 和 Exception 两个子类分别表示错误和异常。
Java 的异常处理通过 5 个关键字来实现:try、catch、throw、throws 和 finally。
try catch 语句用于捕获并处理异常,finally 语句用于在任何情况下都必须执行的代码,throw 语句用于拋出异常,throws 语句用于声明可能会出现的异常。
finally块的语句在try或catch中的return语句执行之后返回之前执行,
且finally里的修改语句可能影响也可能不影响try或catch中 return已经确定的返回值,
判断是否需要调整HashMap的容量
异常
异常(exception)是在运行程序时产生的一种异常情况
在 Java 中所有异常类型都是内置类 java.lang.Throwable 类的子类,即 Throwable 位于异常类层次结构的顶层。
Throwable 类下有两个异常分支 Exception 和 Error,Throwable 类是所有异常和错误的超类,下面有 Error 和 Exception 两个子类分别表示错误和异常。
Java 的异常处理通过 5 个关键字来实现:try、catch、throw、throws 和 finally。
try catch 语句用于捕获并处理异常,finally 语句用于在任何情况下都必须执行的代码,throw 语句用于拋出异常,throws 语句用于声明可能会出现的异常。
finally块的语句在try或catch中的return语句执行之后返回之前执行,
且finally里的修改语句可能影响也可能不影响try或catch中 return已经确定的返回值,
若finally里也有return语句则覆盖try或catch中的return语句直接返回。
原文链接:https://blog.csdn.net/sinat_41541787/article/details/115795319
所属网站分类: 技术文章 > 博客
作者:飞翔公园
链接:http://www.javaheidong.com/blog/article/159484/c14758e42d9ca27bf7c1/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力