

Phoenix入门
发布于2021-05-29 19:13 阅读(1272) 评论(0) 点赞(1) 收藏(4)
Phoenix概述
虽然Hive on SQL对SQL的支持更加全面,但是其不支持二级索引,底层是通过MapReduce实现的。Phoenix是专门为HBASE设计的SQL on HBASE工具,使用Phoenix可以实现基于SQL操作HBASE,使用Phoenix也可以自动构建二级索引并维护二级索引。
Phoenix官网
官网这么介绍它:
Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds:
the power of standard SQL and JDBC APIs with full ACID transaction capabilities and the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store.
Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce.
翻译过来是:
Apache Phoenix通过结合两个方面的优点,在Hadoop中为低延迟应用程序提供OLTP和操作分析:
标准SQL和jdbcapis的强大功能,以及完整的ACID事务处理功能和通过利用HBase作为其后台存储,NoSQL世界中后期绑定的模式读取功能的灵活性。
Apache Phoenix与其他Hadoop产品(如Spark、Hive、Pig、Flume和Map Reduce)完全集成。
翻到最下边还有:

Phoenix官方15分钟快速入门
Phoenix官方语法介绍 这里可以查看Phoenix各种命令的语法。
简言之,Phoenix上层提供了SQL接口,底层通过HBASE的Java API实现,通过构建一系列Scan和Put实现对HBASE数据的读写。
由于底层封装了大量的内置协处理器,Phoenix可以实现各种复杂的处理需求,如:二级索引。Phoenix 对 SQL 相对支持不全面,但是性能比较好,直接使用HbaseAPI,支持索引实现。故Phoenix适用于任何需要使用SQL或者JDBC来快速的读写Hbase的场景,尤其是需要构建/维护二级索引的场景。
Phoenix部署
cd /export/software/
使用rz上传安装包(选用5.0.0版本)后解压及改名:
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /export/server/
cd /export/server/
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix-5.0.0-HBase-2.0-bin
Linux有文件句柄限制,默认是1024,可能不够用,先在3台node的尾部插入这些内容来修改Linux文件句柄数:
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
【*】这个标号必须有,代表所有用户。记得保存。
切换目录并查看:
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
ll -ah
东西还挺多:
[root@node1 phoenix-5.0.0-HBase-2.0-bin]# ll -ah
总用量 464M
drwxr-xr-x 5 502 games 4.0K 6月 27 2018 .
drwxr-xr-x. 9 root root 178 5月 27 17:37 ..
drwxr-xr-x 4 502 games 4.0K 5月 27 17:37 bin
drwxr-xr-x 3 502 games 133 5月 27 17:37 examples
-rw-r--r-- 1 502 games 141K 6月 27 2018 LICENSE
-rw-r--r-- 1 502 games 11K 6月 27 2018 NOTICE
-rw-r--r-- 1 502 games 129M 6月 27 2018 phoenix-5.0.0-HBase-2.0-client.jar
-rw-r--r-- 1 502 games 106M 6月 27 2018 phoenix-5.0.0-HBase-2.0-hive.jar
-rw-r--r-- 1 502 games 132M 6月 27 2018 phoenix-5.0.0-HBase-2.0-pig.jar
-rw-r--r-- 1 502 games 7.6M 6月 27 2018 phoenix-5.0.0-HBase-2.0-queryserver.jar
-rw-r--r-- 1 502 games 40M 6月 27 2018 phoenix-5.0.0-HBase-2.0-server.jar
-rw-r--r-- 1 502 games 33M 6月 27 2018 phoenix-5.0.0-HBase-2.0-thin-client.jar
-rw-r--r-- 1 502 games 4.2M 6月 27 2018 phoenix-core-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 2.5M 6月 27 2018 phoenix-core-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 2.4M 6月 27 2018 phoenix-core-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 47K 6月 27 2018 phoenix-flume-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 30K 6月 27 2018 phoenix-flume-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 37K 6月 27 2018 phoenix-flume-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 137K 6月 27 2018 phoenix-hive-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 84K 6月 27 2018 phoenix-hive-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 77K 6月 27 2018 phoenix-hive-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 27K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 686K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0-minimal.jar
-rw-r--r-- 1 502 games 17K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 24K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 23K 6月 27 2018 phoenix-load-balancer-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 13K 6月 27 2018 phoenix-load-balancer-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 164K 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 3.5M 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0-minimal.jar
-rw-r--r-- 1 502 games 116K 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 70K 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 45K 6月 27 2018 phoenix-pig-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 30K 6月 27 2018 phoenix-pig-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 46K 6月 27 2018 phoenix-pig-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 31K 6月 27 2018 phoenix-queryserver-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 23K 6月 27 2018 phoenix-queryserver-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 59K 6月 27 2018 phoenix-queryserver-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 17K 6月 27 2018 phoenix-queryserver-client-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 14K 6月 27 2018 phoenix-queryserver-client-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 11K 6月 27 2018 phoenix-queryserver-client-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 87K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 3.5K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0-javadoc.jar
-rw-r--r-- 1 502 games 25K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 125K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 16K 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 2.7M 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0-runnable.jar
-rw-r--r-- 1 502 games 12K 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 7.9K 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0-tests.jar
drwxr-xr-x 6 502 games 236 5月 27 17:37 python
-rw-r--r-- 1 502 games 1.2K 6月 27 2018 README.md
这些jar包可以作为HBASE的依赖库,先:
cp phoenix-* /export/server/hbase-2.1.0/lib/
cd /export/server/hbase-2.1.0/lib/
再分发给node2和node3:
scp phoenix-* node2:$PWD
scp phoenix-* node3:$PWD
修改node1的hbase-site.xml:
cd /export/server/hbase-2.1.0/conf/
vim hbase-site.xml
在configuration之间插入:
<!-- 关闭流检查,从2.x开始使用async -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 支持HBase命名空间映射 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<!-- 支持索引预写日志编码 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
保存后同步给node2和node3:
scp hbase-site.xml node2:$PWD
scp hbase-site.xml node3:$PWD
PWD是大写!!!
由于Phoenix也需要加载配置文件:
[root@node1 conf]# cp hbase-site.xml /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/
cp:是否覆盖"/export/server/phoenix-5.0.0-HBase-2.0-bin/bin/hbase-site.xml"? yes
直接yes覆盖。安全起见再查看下:
cat /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/hbase-site.xml
如果启动了HBASE需要重启HBASE才能刷新配置。。。笔者故意先不启动就是为了省去重启这一步。。。机智如我。。。按顺序启动HBASE即可(启动HDFS+YARN+Zookeeper→启动HBASE服务端→启动hbase shell)。
Phoenix启动
新建立node1会话:
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
[root@node1 phoenix-5.0.0-HBase-2.0-bin]# ll ./bin -ah
总用量 152K
drwxr-xr-x 4 502 games 4.0K 5月 27 17:37 .
drwxr-xr-x 5 502 games 4.0K 6月 27 2018 ..
drwxr-xr-x 2 502 games 25 5月 27 17:37 argparse-1.4.0
drwxr-xr-x 4 502 games 101 5月 27 17:37 config
-rw-r--r-- 1 502 games 33K 6月 27 2018 daemon.py
-rwxr-xr-x 1 502 games 1.9K 6月 27 2018 end2endTest.py
-rw-r--r-- 1 502 games 1.6K 6月 27 2018 hadoop-metrics2-hbase.properties
-rw-r--r-- 1 502 games 3.0K 6月 27 2018 hadoop-metrics2-phoenix.properties
-rw-r--r-- 1 502 games 1.9K 5月 27 19:39 hbase-site.xml
-rw-r--r-- 1 502 games 2.6K 6月 27 2018 log4j.properties
-rwxr-xr-x 1 502 games 5.1K 6月 27 2018 performance.py
-rwxr-xr-x 1 502 games 3.2K 6月 27 2018 pherf-cluster.py
-rwxr-xr-x 1 502 games 2.7K 6月 27 2018 pherf-standalone.py
-rwxr-xr-x 1 502 games 2.1K 6月 27 2018 phoenix_sandbox.py
-rwxr-xr-x 1 502 games 9.5K 6月 27 2018 phoenix_utils.py
-rwxr-xr-x 1 502 games 2.7K 6月 27 2018 psql.py
-rwxr-xr-x 1 502 games 7.6K 6月 27 2018 queryserver.py
-rw-r--r-- 1 502 games 1.8K 6月 27 2018 readme.txt
-rw-r--r-- 1 502 games 1.7K 6月 27 2018 sandbox-log4j.properties
-rwxr-xr-x 1 502 games 4.7K 6月 27 2018 sqlline.py
-rwxr-xr-x 1 502 games 6.6K 6月 27 2018 sqlline-thin.py
-rwxr-xr-x 1 502 games 6.8K 6月 27 2018 tephra
-rw-r--r-- 1 502 games 2.0K 6月 27 2018 tephra-env.sh
-rwxr-xr-x 1 502 games 6.8K 6月 27 2018 traceserver.py
在bin目录内有个sqlline.py,这货是个Python写的启动脚本,运行它就能启动Phoenix:
bin/sqlline.py node1:2181
在node1:16010查看HBASE的表:
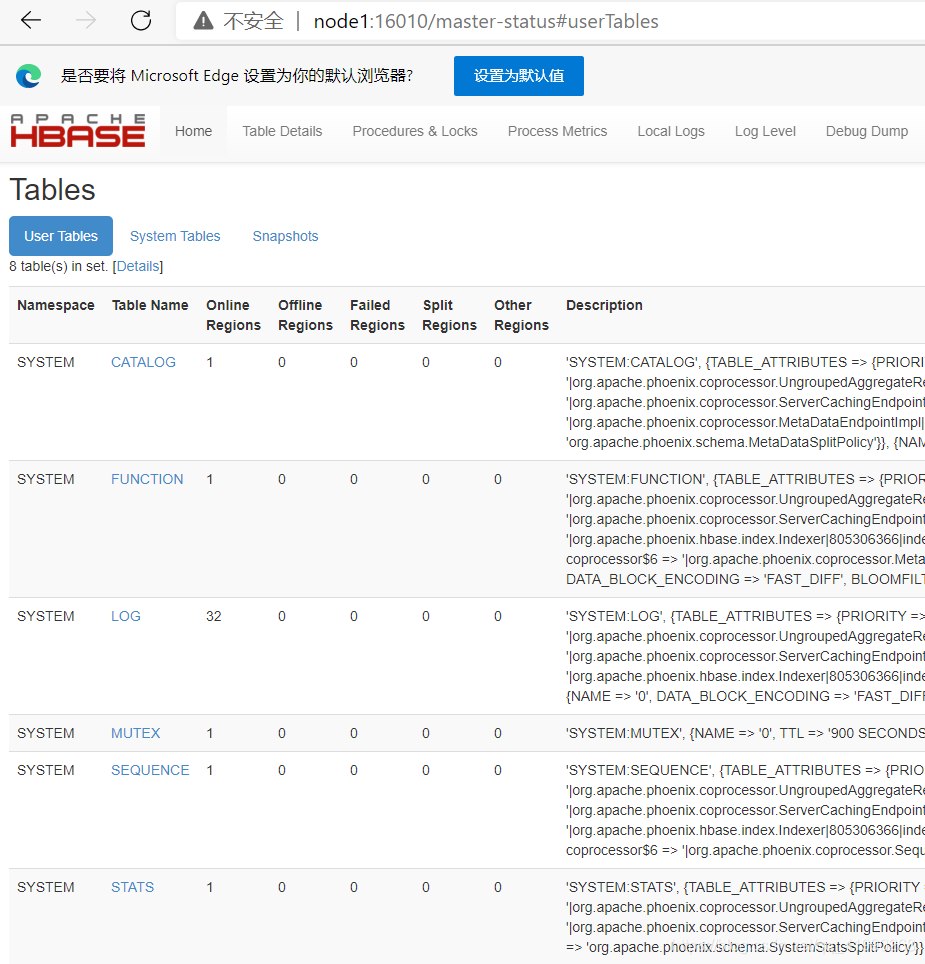
比之前多了几个表,肯定不是笔者自己建立的。。。正好Phoenix也启动了,使用!tables看看:
0: jdbc:phoenix:node1:2181> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
0: jdbc:phoenix:node1:2181>
是它创建的。。。那么Phoenix也就部署完毕。使用!quit即可退出。
命令行使用
可以在上文中的官网指导手册查看帮助。使用!help也可查看一些帮助。
DDL
操作NameSpace
创建NameSpace
在Phoenix的命令行:
0: jdbc:phoenix:node1:2181> create schema if not exists student;
No rows affected (0.274 seconds)
在hbase shell:
hbase(main):001:0> list_namespace
NAMESPACE
STUDENT
SYSTEM
default
hbase
test210524
test210525
6 row(s)
Took 0.5744 seconds
好吧。。。全是大写字母!!!如果要使用小写字母需要+""双引号。
切换NameSpace
0: jdbc:phoenix:node1:2181> use student;
No rows affected (0.02 seconds)
删除NameSpace
0: jdbc:phoenix:node1:2181> drop schema if exists student;
No rows affected (0.274 seconds)
操作Table
列举
上方使用!table列举过了。
创建
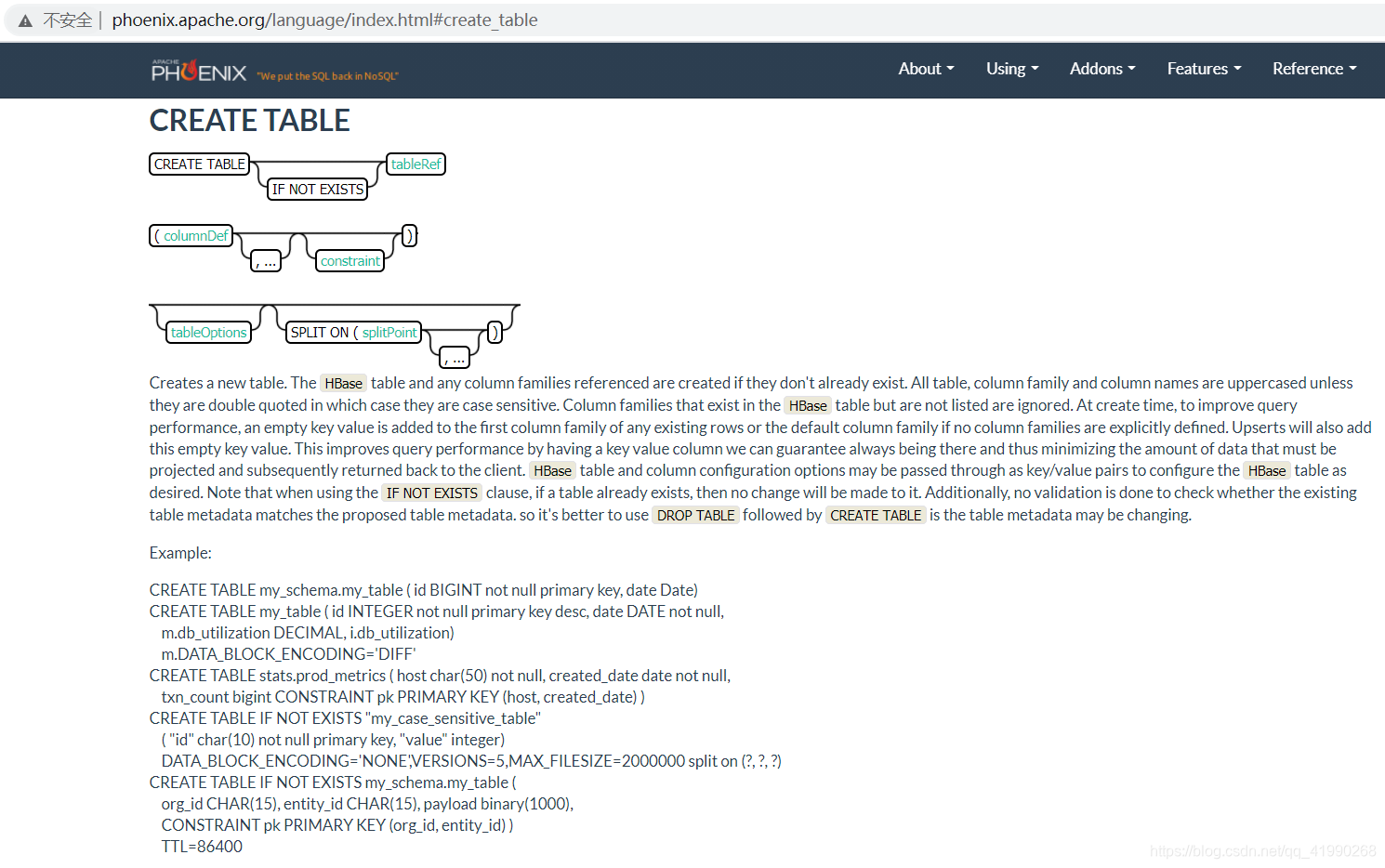
官网给的还比较全面。。。也可以自己试试:
CREATE TABLE my_schema.my_table (
id BIGINT not null primary key,
date Date
);
HBASE当然是没有主键的,这个主键就是HBASE的Rowkey。
CREATE TABLE my_table (
id INTEGER not null primary key desc,
m.date DATE not null,
m.db_utilization DECIMAL,
i.db_utilization
) m.VERSIONS='3';
这种写法就是指定了列族(此处m和i)的列。
CREATE TABLE stats.prod_metrics (
host char(50) not null,
created_date date not null,
txn_count bigint
CONSTRAINT pk PRIMARY KEY (host, created_date)
);
HBASE必须有Rowkey,∴无论如何也得指定一个(此处构建主键,其实就是用多个字段组合出Rowkey)。
CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"(
"id" char(10) not null primary key,
"value" integer
) DATA_BLOCK_ENCODING='NONE',VERSIONS=5,MAX_FILESIZE=2000000
split on (?, ?, ?);
还可以使用split on来指定预分区。
CREATE TABLE IF NOT EXISTS my_schema.my_table (
org_id CHAR(15),
entity_id CHAR(15),
payload binary(1000),
CONSTRAINT pk PRIMARY KEY (org_id, entity_id)
) TTL=86400
这种写法是指定有效期为86400ms。
如果HBASE中没有同名表,就会自动创建一个,例如上文中看到的只有5个表,在Phoenix命令行中执行:
use default;
create table if not exists ORDER_DTL(
ID varchar primary key,
C1.STATUS varchar,
C1.PAY_MONEY float,
C1.PAYWAY integer,
C1.USER_ID varchar,
C1.OPERATION_DATE varchar,
C1.CATEGORY varchar
);
执行后:
0: jdbc:phoenix:node1:2181> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | |
| | | ORDER_DTL | TABLE | | | | | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
0: jdbc:phoenix:node1:2181>
一般不会有人这么做。。。Phoenix的主要用途是查询。。。想要查询就得事先有表和数据。。。那么,先准备一个表和数据再说。。。使用shell脚本来做这件事:
cd /export/data/
rz上传数据
vim /export/data/hbasedata20210527.sh
插入:
#!/bin/bash
hbase shell /export/data/ORDER_INFO.txt
保存后+运行权限:
chmod u+x hbasedata20210527.sh
执行:
hbasedata20210527.sh
Java API的DDL利用之前写的程序读取:
tableDescriptor.getTableName().getNameAsString() = ORDER_DTL
tableDescriptor.getTableName().getNameAsString() = ORDER_INFO
tableDescriptor.getTableName().getNameAsString() = SYSTEM:CATALOG
tableDescriptor.getTableName().getNameAsString() = SYSTEM:FUNCTION
tableDescriptor.getTableName().getNameAsString() = SYSTEM:LOG
tableDescriptor.getTableName().getNameAsString() = SYSTEM:MUTEX
tableDescriptor.getTableName().getNameAsString() = SYSTEM:SEQUENCE
tableDescriptor.getTableName().getNameAsString() = SYSTEM:STATS
tableDescriptor.getTableName().getNameAsString() = test210524:t1
tableDescriptor.getTableName().getNameAsString() = test210525:testTable1
居然没有命名空间!!!其实也无妨:
hbase(main):010:0> list
TABLE
ORDER_DTL
ORDER_INFO
SYSTEM:CATALOG
SYSTEM:FUNCTION
SYSTEM:LOG
SYSTEM:MUTEX
SYSTEM:SEQUENCE
SYSTEM:STATS
test210524:t1
test210525:testTable1
10 row(s)
Took 0.0524 seconds
=> ["ORDER_DTL", "ORDER_INFO", "SYSTEM:CATALOG", "SYSTEM:FUNCTION", "SYSTEM:LOG", "SYSTEM:MUTEX", "SYSTEM:SEQUENCE", "SYSTEM:STATS", "test210524:t1", "test210525:testTable1"]
hbase(main):011:0>
虽然这2张表并没有命名空间,但是看样子已经成功创建了表。更神奇的是:
0: jdbc:phoenix:node1:2181> create table if not exists ORDER_INFO(
. . . . . . . . . . . . . > "ROW" varchar primary key,
. . . . . . . . . . . . . > "C1"."USER_ID" varchar,
. . . . . . . . . . . . . > "C1"."OPERATION_DATE" varchar,
. . . . . . . . . . . . . > "C1"."PAYWAY" varchar,
. . . . . . . . . . . . . > "C1"."PAY_MONEY" varchar,
. . . . . . . . . . . . . > "C1"."STATUS" varchar,
. . . . . . . . . . . . . > "C1"."CATEGORY" varchar
. . . . . . . . . . . . . > ) column_encoded_bytes=0 ;
66 rows affected (6.647 seconds)
0: jdbc:phoenix:node1:2181>
貌似Phoenix检测到这张表存在了,并且自动关联:
0: jdbc:phoenix:node1:2181> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | |
| | | ORDER_DTL | TABLE | | | | | |
| | | ORDER_INFO | TABLE | | | | | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
0: jdbc:phoenix:node1:2181>
简单查询下(为了节省篇幅,缩减一些):
0: jdbc:phoenix:node1:2181> select * from ORDER_INFO;
+---------------------------------------+----------+----------------------+---------+------------+---------+------------+
| ROW | USER_ID | OPERATION_DATE | PAYWAY | PAY_MONEY | STATUS | CATEGORY |
+---------------------------------------+----------+----------------------+---------+------------+---------+------------+
| 02602f66-adc7-40d4-8485-76b5632b5b53 | 4944191 | 2020-04-25 12:09:16 | 1 | 4070 | 已提交 | 手机; |
| 0968a418-f2bc-49b4-b9a9-2157cf214cfd | 1625615 | 2020-04-25 12:09:37 | 1 | 4350 | 已完成 | 家用电器;;电脑; |
| 0e01edba-5e55-425e-837a-7efb91c56630 | 3919700 | 2020-04-25 12:09:44 | 3 | 6370 | 已付款 | 男装;男鞋; |
| 0f46d542-34cb-4ef4-b7fe-6dcfa5f14751 | 2993700 | 2020-04-25 12:09:46 | 1 | 9380 | 已付款 | 维修;手机; |
| 1fb7c50f-9e26-4aa8-a140-a03d0de78729 | 5037058 | 2020-04-25 12:10:13 | 2 | 6400 | 已完成 | 数码;女装; |
| f642b16b-eade-4169-9eeb-4d5f294ec594 | 6463215 | 2020-04-25 12:09:33 | 1 | 4010 | 已付款 | 男鞋;汽车; |
| f8f3ca6f-2f5c-44fd-9755-1792de183845 | 4060214 | 2020-04-25 12:09:12 | 3 | 5950 | 已付款 | 机票;文娱; |
+---------------------------------------+----------+----------------------+---------+------------+---------+------------+
66 rows selected (0.135 seconds)
0: jdbc:phoenix:node1:2181>
这种先有表和数据,然后关联及查询的做法才是Phoenix常用的方式!!!
查看
0: jdbc:phoenix:node1:2181> !desc order_info;
+------------+--------------+-------------+-----------------+------------+------------+--------------+----------------+------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | DATA_TYPE | TYPE_NAME | COLUMN_SIZE | BUFFER_LENGTH | DECIMAL_DI |
+------------+--------------+-------------+-----------------+------------+------------+--------------+----------------+------------+
| | | ORDER_INFO | ROW | 12 | VARCHAR | null | null | null |
| | | ORDER_INFO | USER_ID | 12 | VARCHAR | null | null | null |
| | | ORDER_INFO | OPERATION_DATE | 12 | VARCHAR | null | null | null |
| | | ORDER_INFO | PAYWAY | 12 | VARCHAR | null | null | null |
| | | ORDER_INFO | PAY_MONEY | 12 | VARCHAR | null | null | null |
| | | ORDER_INFO | STATUS | 12 | VARCHAR | null | null | null |
| | | ORDER_INFO | CATEGORY | 12 | VARCHAR | null | null | null |
+------------+--------------+-------------+-----------------+------------+------------+--------------+----------------+------------+
0: jdbc:phoenix:node1:2181>
删除
drop table if exists order_dtl;
DML
upsert
语法类似于insert,由于HBASE的机制是覆盖(Overwrite)代替插入(insert)/更新(update),同样的语法可以:
upsert into order_info values('z8f3ca6f-2f5c-44fd-9755-1792de183845','4944191','2020-04-25 12:09:16','1','4070','未提交','电脑');
插入数据,也可以:
upsert into order_info("ROW","USER_ID") values('z8f3ca6f-2f5c-44fd-9755-1792de183845','123456');
更新数据。
delete
delete from order_info where USER_ID = '123456';
与MySQL基本一致。
select
select "ROW",payway,pay_money,category from order_info where payway = '1';
select
payway,
count(distinct user_id) as numb
from order_info
group by payway
order by numb desc;
select * from order_info limit 6 offset 60;
这条限制显示60~66行的SQL和MySQL不太像。与MySQL很像的也不少,具体参照上文的Phoenix官方功能介绍,里边有很多SQL函数的用法。
预分区
设计表是就需要根据Rowkey来设计多个分区,尽量避免数据倾斜可能导致HBASE的热点问题。
指定分区范围可以参照这种套路:
CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"(
"id" char(10) not null primary key,
"value" integer
)
DATA_BLOCK_ENCODING='NONE',VERSIONS=5,MAX_FILESIZE=2000000 split on (?, ?, ?)
Phoenix命令行中试试:
drop table if exists ORDER_DTL;
create table if not exists ORDER_DTL(
"id" varchar primary key,
C1."status" varchar,
C1."money" float,
C1."pay_way" integer,
C1."user_id" varchar,
C1."operation_time" varchar,
C1."category" varchar
)
CONPRESSION='GZ'
SPLIT ON ('3','5','7');
在浏览器的node1:16010→Table Detas→ORDER_DTL→往下翻可以看到:
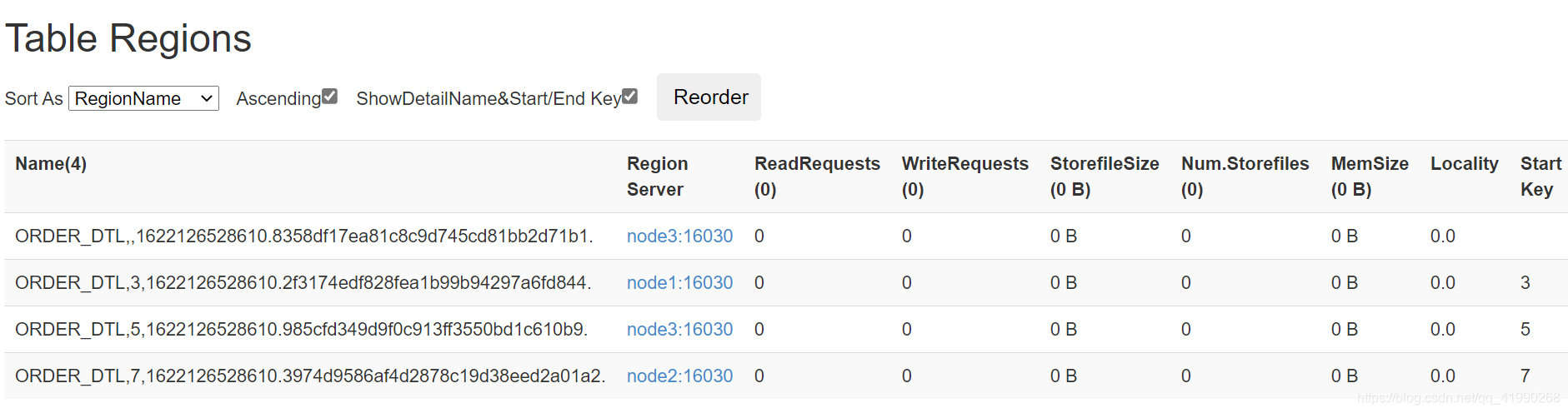
显然预分了4个区。图糊了,看重点:
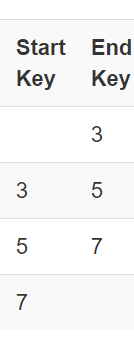
按照分区条件,分了这么4个区。插入一波数据后刷新网页:
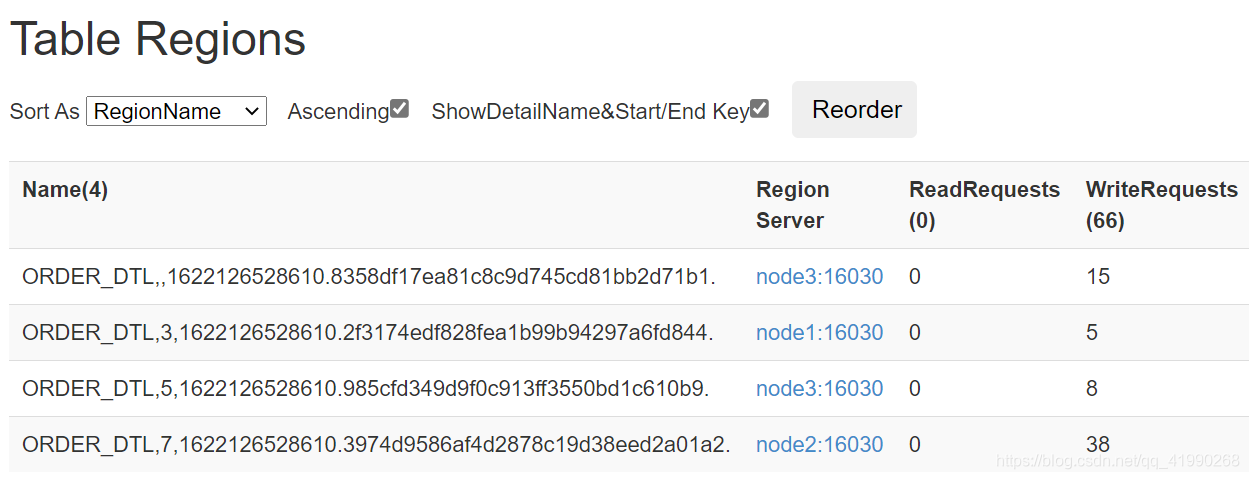
貌似插入成功。但是负载并不均衡:

scan 'ORDER_DTL'
执行后尾部是这样:
f8f3ca6f-2f5c-44fd-9755-1792de183 column=C1:\x80\x0C, timestamp=1622127301702, value=\xC5\xB9\xF0\x01
845
f8f3ca6f-2f5c-44fd-9755-1792de183 column=C1:\x80\x0D, timestamp=1622127301702, value=\x80\x00\x00\x03
845
f8f3ca6f-2f5c-44fd-9755-1792de183 column=C1:\x80\x0E, timestamp=1622127301702, value=4060214
845
f8f3ca6f-2f5c-44fd-9755-1792de183 column=C1:\x80\x0F, timestamp=1622127301702, value=2020-04-25 12:09:12
845
f8f3ca6f-2f5c-44fd-9755-1792de183 column=C1:\x80\x10, timestamp=1622127301702, value=\xE6\x9C\xBA\xE7\xA5\xA8;\xE6\x96\x87\xE5\xA8\
845 xB1;
65 row(s)
Took 0.6949 seconds
加盐salt
Rowkey在设计的时候为了避免连续,需要构建Rowkey的散列。但不能确保Rowkey任何情况都一定是散列,万一是有序的呢?
这就需要在Phoenix创建一张盐表,写入的数据会自动进行编码写入不同的分区中。例如这种套路:
CREATE TABLE table (
a_key VARCHAR PRIMARY KEY,
a_col VARCHAR
) SALT_BUCKETS = 20;
使用Phoenix命令行建个盐表试试:
drop table if exists ORDER_DTL;
create table if not exists ORDER_DTL(
"id" varchar primary key,
C1."status" varchar,
C1."money" float,
C1."pay_way" integer,
C1."user_id" varchar,
C1."operation_time" varchar,
C1."category" varchar
)
CONPRESSION='GZ', SALT_BUCKETS=10;
插入同样的数据后:
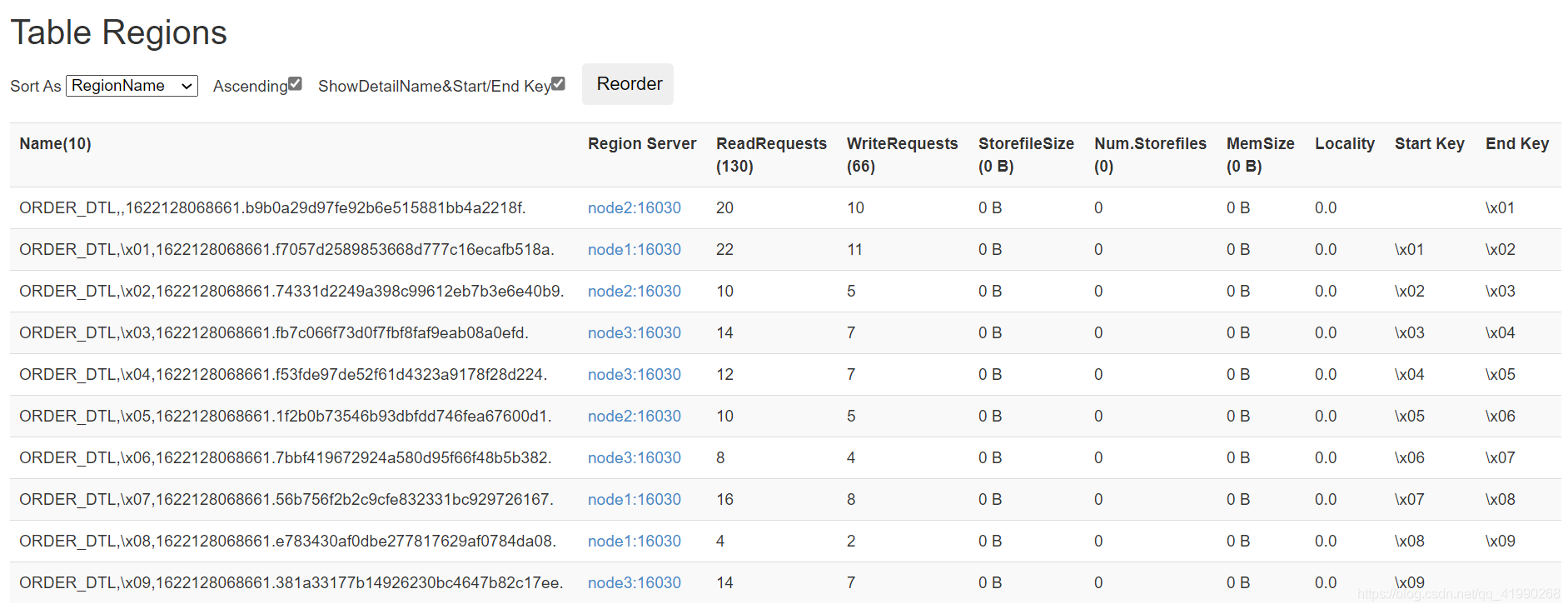
显然自动设置了分区:

负载相对均衡:
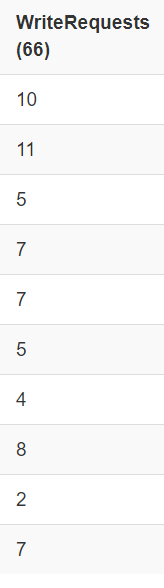
scan 'ORDER_DTL'
执行后尾部是这样:
\x09e180a9f2-9f80-4b6d-99c8-452d6 column=C1:\x80\x0B, timestamp=1622128100372, value=\xE5\xB7\xB2\xE5\xAE\x8C\xE6\x88\x90
c037fc7
\x09e180a9f2-9f80-4b6d-99c8-452d6 column=C1:\x80\x0C, timestamp=1622128100372, value=\xC5\xFD\xC0\x01
c037fc7
\x09e180a9f2-9f80-4b6d-99c8-452d6 column=C1:\x80\x0D, timestamp=1622128100372, value=\x80\x00\x00\x02
c037fc7
\x09e180a9f2-9f80-4b6d-99c8-452d6 column=C1:\x80\x0E, timestamp=1622128100372, value=7645270
c037fc7
\x09e180a9f2-9f80-4b6d-99c8-452d6 column=C1:\x80\x0F, timestamp=1622128100372, value=2020-04-25 12:09:32
c037fc7
\x09e180a9f2-9f80-4b6d-99c8-452d6 column=C1:\x80\x10, timestamp=1622128100372, value=\xE7\x94\xB7\xE9\x9E\x8B;\xE6\xB1\xBD\xE8\xBD\
c037fc7 xA6;
65 row(s)
Took 1.3174 seconds
由Phoenix来实现自动编码,可以解决Rowkey的热点问题,不需要自己设计散列的Rowkey。但是!!!一旦使用了盐表,对于盐表数据的操作只能通过Phoenix来实现。
视图
直接关联Hbase中的表,会导致误删除,对数据的权限会有影响,容易出现问题。
Phoenix中建议使用视图的方式来关联Hbase中已有的表。通过构建关联视图(视图可以看作只读的表),可以解决大部分需要查询的数据,且不影响数据安全。
在Phoenix命令行:
create view if not exists "MOMO_CHAT"."MSG" (
"pk" varchar primary key, -- 指定ROWKEY映射到主键
"C1"."msg_time" varchar,
"C1"."sender_nickyname" varchar,
"C1"."sender_account" varchar,
"C1"."sender_sex" varchar,
"C1"."sender_ip" varchar,
"C1"."sender_os" varchar,
"C1"."sender_phone_type" varchar,
"C1"."sender_network" varchar,
"C1"."sender_gps" varchar,
"C1"."receiver_nickyname" varchar,
"C1"."receiver_ip" varchar,
"C1"."receiver_account" varchar,
"C1"."receiver_os" varchar,
"C1"."receiver_phone_type" varchar,
"C1"."receiver_network" varchar,
"C1"."receiver_gps" varchar,
"C1"."receiver_sex" varchar,
"C1"."msg_type" varchar,
"C1"."distance" varchar
);
select
"pk",
"C1"."msg_time",
"C1"."sender_account",
"C1"."receiver_account"
from "MOMO_CHAT"."MSG"
limit 10;
想使用得先有命名空间、表及数据,否则?
Error: ERROR 505 (42000): Table is read only. (state=42000,code=505)
org.apache.phoenix.schema.ReadOnlyTableException: ERROR 505 (42000): Table is read only.
at org.apache.phoenix.query.ConnectionQueryServicesImpl.ensureTableCreated(ConnectionQueryServicesImpl.java:1126)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.createTable(ConnectionQueryServicesImpl.java:1501)
at org.apache.phoenix.schema.MetaDataClient.createTableInternal(MetaDataClient.java:2721)
at org.apache.phoenix.schema.MetaDataClient.createTable(MetaDataClient.java:1114)
at org.apache.phoenix.compile.CreateTableCompiler$1.execute(CreateTableCompiler.java:192)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:408)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:391)
at org.apache.phoenix.call.CallRunner.run(CallRunner.java:53)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:390)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:378)
at org.apache.phoenix.jdbc.PhoenixStatement.execute(PhoenixStatement.java:1825)
at sqlline.Commands.execute(Commands.java:822)
at sqlline.Commands.sql(Commands.java:732)
at sqlline.SqlLine.dispatch(SqlLine.java:813)
at sqlline.SqlLine.begin(SqlLine.java:686)
at sqlline.SqlLine.start(SqlLine.java:398)
at sqlline.SqlLine.main(SqlLine.java:291)
Error: ERROR 1012 (42M03): Table undefined. tableName=MOMO_CHAT.MSG (state=42M03,code=1012)
org.apache.phoenix.schema.TableNotFoundException: ERROR 1012 (42M03): Table undefined. tableName=MOMO_CHAT.MSG
at org.apache.phoenix.compile.FromCompiler$BaseColumnResolver.createTableRef(FromCompiler.java:577)
at org.apache.phoenix.compile.FromCompiler$SingleTableColumnResolver.<init>(FromCompiler.java:391)
at org.apache.phoenix.compile.FromCompiler.getResolverForQuery(FromCompiler.java:228)
at org.apache.phoenix.compile.FromCompiler.getResolverForQuery(FromCompiler.java:206)
at org.apache.phoenix.jdbc.PhoenixStatement$ExecutableSelectStatement.compilePlan(PhoenixStatement.java:482)
at org.apache.phoenix.jdbc.PhoenixStatement$ExecutableSelectStatement.compilePlan(PhoenixStatement.java:456)
at org.apache.phoenix.jdbc.PhoenixStatement$1.call(PhoenixStatement.java:302)
at org.apache.phoenix.jdbc.PhoenixStatement$1.call(PhoenixStatement.java:291)
at org.apache.phoenix.call.CallRunner.run(CallRunner.java:53)
at org.apache.phoenix.jdbc.PhoenixStatement.executeQuery(PhoenixStatement.java:290)
at org.apache.phoenix.jdbc.PhoenixStatement.executeQuery(PhoenixStatement.java:283)
at org.apache.phoenix.jdbc.PhoenixStatement.execute(PhoenixStatement.java:1830)
at sqlline.Commands.execute(Commands.java:822)
at sqlline.Commands.sql(Commands.java:732)
at sqlline.SqlLine.dispatch(SqlLine.java:813)
at sqlline.SqlLine.begin(SqlLine.java:686)
at sqlline.SqlLine.start(SqlLine.java:398)
at sqlline.SqlLine.main(SqlLine.java:291)
可以,这很Java。
JDBC操作Phoenix
准备工作
放置资源文件:
JDBC操作Phoenix的方式必须确保可以读取到HBASE的配置文件(Linux集群中的同一个hbase-site.xml)。log4j是看日志的,没啥用。
在pom.xml中配置Maven依赖:
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<properties>
<hbase.version>2.1.2</hbase.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- Xml操作相关 -->
<dependency>
<groupId>com.github.cloudecho</groupId>
<artifactId>xmlbean</artifactId>
<version>1.5.5</version>
</dependency>
<!-- 操作Office库 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.0.1</version>
</dependency>
<!-- 操作Office库 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.0.1</version>
</dependency>
<!-- 操作Office库 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>4.0.1</version>
</dependency>
<!-- 操作JSON -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<!-- phoenix core -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<!-- phoenix 客户端 -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
</dependencies>
咳。。。咳。。。咳。。。你懂的。
代码实现
public class PhoenixChatMessageService implements ChatMessageService {
private Connection connection;
public PhoenixChatMessageService() throws ClassNotFoundException, SQLException {
try {
//申明驱动类
Class.forName(PhoenixDriver.class.getName());
// System.out.println(PhoenixDriver.class.getName());
//构建连接
connection = DriverManager.getConnection("jdbc:phoenix:node1,node2,node3:2181");
} catch (ClassNotFoundException e) {
throw new RuntimeException("加载Phoenix驱动失败!");
} catch (SQLException e) {
throw new RuntimeException("获取Phoenix JDBC连接失败!");
}
}
@Override
public List<Msg> getMessage(String date, String sender, String receiver) throws Exception {
PreparedStatement ps = connection.prepareStatement(
"SELECT * FROM MOMO_CHAT.MSG T WHERE substr(\"msg_time\", 0, 10) = ? "
+ "AND T.\"sender_account\" = ? "
+ "AND T.\"receiver_account\" = ? ");
ps.setString(1, date);
ps.setString(2, sender);
ps.setString(3, receiver);
ResultSet rs = ps.executeQuery();
List<Msg> msgList = new ArrayList<>();
while(rs.next()) {
Msg msg = new Msg();
msg.setMsg_time(rs.getString("msg_time"));
msg.setSender_nickyname(rs.getString("sender_nickyname"));
msg.setSender_account(rs.getString("sender_account"));
msg.setSender_sex(rs.getString("sender_sex"));
msg.setSender_ip(rs.getString("sender_ip"));
msg.setSender_os(rs.getString("sender_os"));
msg.setSender_phone_type(rs.getString("sender_phone_type"));
msg.setSender_network(rs.getString("sender_network"));
msg.setSender_gps(rs.getString("sender_gps"));
msg.setReceiver_nickyname(rs.getString("receiver_nickyname"));
msg.setReceiver_ip(rs.getString("receiver_ip"));
msg.setReceiver_account(rs.getString("receiver_account"));
msg.setReceiver_os(rs.getString("receiver_os"));
msg.setReceiver_phone_type(rs.getString("receiver_phone_type"));
msg.setReceiver_network(rs.getString("receiver_network"));
msg.setReceiver_gps(rs.getString("receiver_gps"));
msg.setReceiver_sex(rs.getString("receiver_sex"));
msg.setMsg_type(rs.getString("msg_type"));
msg.setDistance(rs.getString("distance"));
msgList.add(msg);
}
return msgList;
}
@Override
public void close() {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
ChatMessageService chatMessageService = new PhoenixChatMessageService();
List<Msg> message = chatMessageService.getMessage("2021-05-27这里写日期", "筛选条件1", "筛选条件2");
for (Msg msg : message) {
System.out.println(msg);
}
chatMessageService.close();
}
}
Maven被墙了,不跑了。。。和JDBC操作MySQL的套路很像。
原文链接:https://blog.csdn.net/qq_41990268/article/details/117332993
所属网站分类: 技术文章 > 博客
作者:我是不是很美
链接:http://www.javaheidong.com/blog/article/207081/7796e501f2ada2af8e49/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力