

flink学习(四)datasetAPI
发布于2021-05-29 20:18 阅读(1383) 评论(0) 点赞(26) 收藏(1)
创建maven项目
傻瓜式一步步的搭建进行
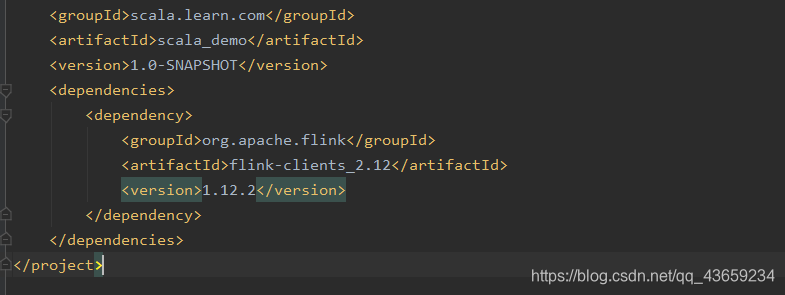
配置一下pom.xml
编写WordCount
package flink_learn;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import scala.Int;
/**
* @author 公羽
* @time : 2021/5/14 12:11
* @File : Wordcount.java
*/
public class Wordcount {
public static void main(String args[]) throws Exception {
//1、准备环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//单例模式
//2、准备数据-source
DataSet<String> lineDS = env.fromElements("spark sqoop hadoop","spark flink","hadoop fink spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataSet<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.2 对集合中的每个单词记为1
DataSet<Tuple2<String,Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataSet<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.4 对结果排序
DataSet<Tuple2<String,Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
//4、输出结果-sink
result.print();
//5、触发执行-execute
//说明:如果有pring那么Dataset不需要调用excute,DataStream需要调用execute
}
}

基于DataStream改写代码
package flink_learn;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author 公羽
* @time : 2021/5/21 9:31
* @File : WordcouhtDataStream.java
*/
public class WordcouhtDataStream {
public static void main(String args[]) throws Exception {
//1、准备环境-env
//新版本的流批统一api,既支持流处理也指出批处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//批处理模式//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//流处理模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动选择处理模式
//2、准备数据-source
DataStream<String> lineDS = env.fromElements("spark sqoop hadoop","spark flink","hadoop fink spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.2 对集合中的每个单词记为1
DataStream<Tuple2<String,Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
//UnsortedGrouping<Tuple2<String,Integer>> groupedDS = wordAndOnesDS.groupBy(0);
KeyedStream<Tuple2<String,Integer>,String> groupedDS = wordAndOnesDS.keyBy(t->t.f0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
//3.5 对结果排序
//DataSet<Tuple2<String,Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
//4、输出结果-sink
result.print();
//5、触发执行-execute
//说明:如果有print那么Dataset不需要调用execute,DataStream需要调用execute
env.execute();
}
}
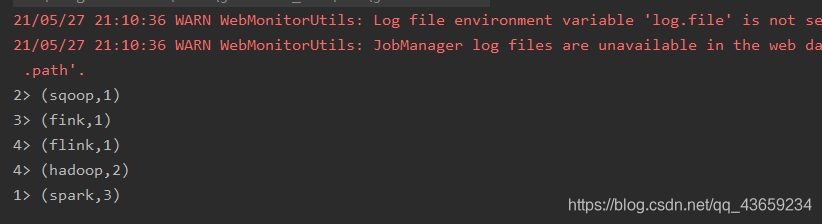
Yarn上运行
添加依赖
在pom文件中加入以下内容
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
打包

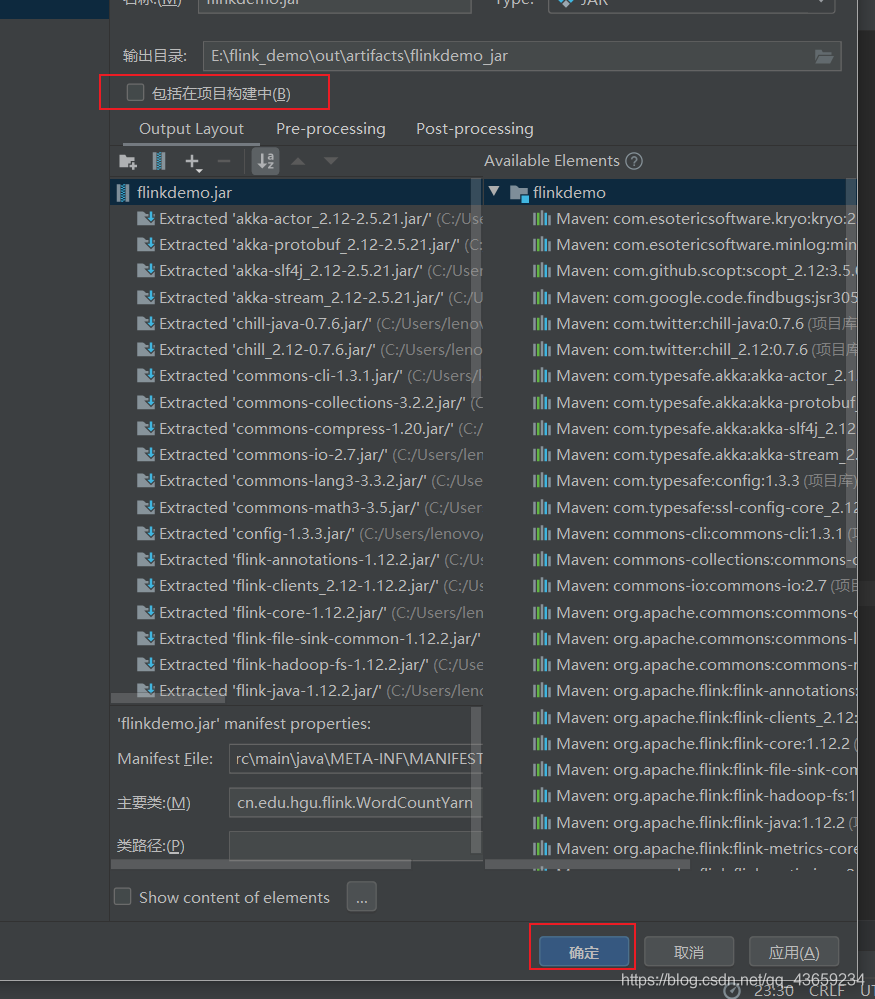
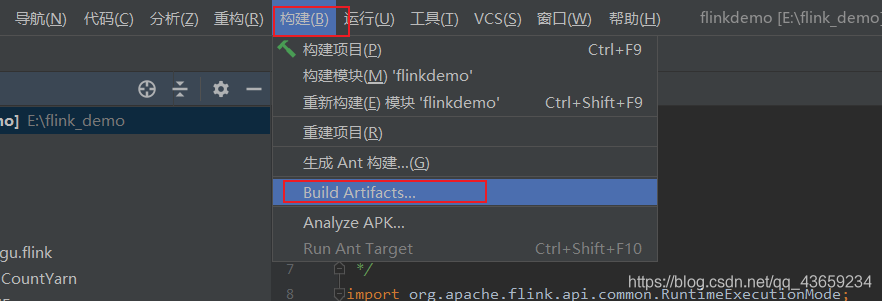
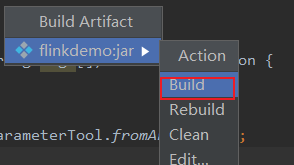
然后等待就行
好了后会产生一个out文件,jar包就在里面
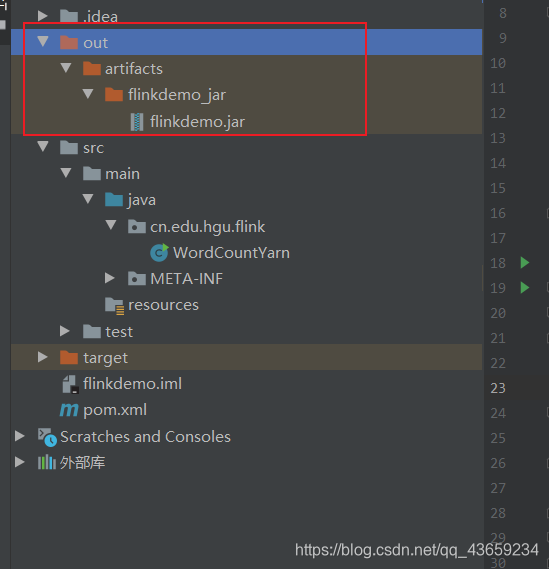
将jar包上传至集群中
将其改名方便点
执行代码
[root@master1 jar]# flink run -Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 1024 -ytm 1024 -c cn.edu.hgu.flink.WordCountYarn /root/jar/wc.jar
其中主方法的路径如下
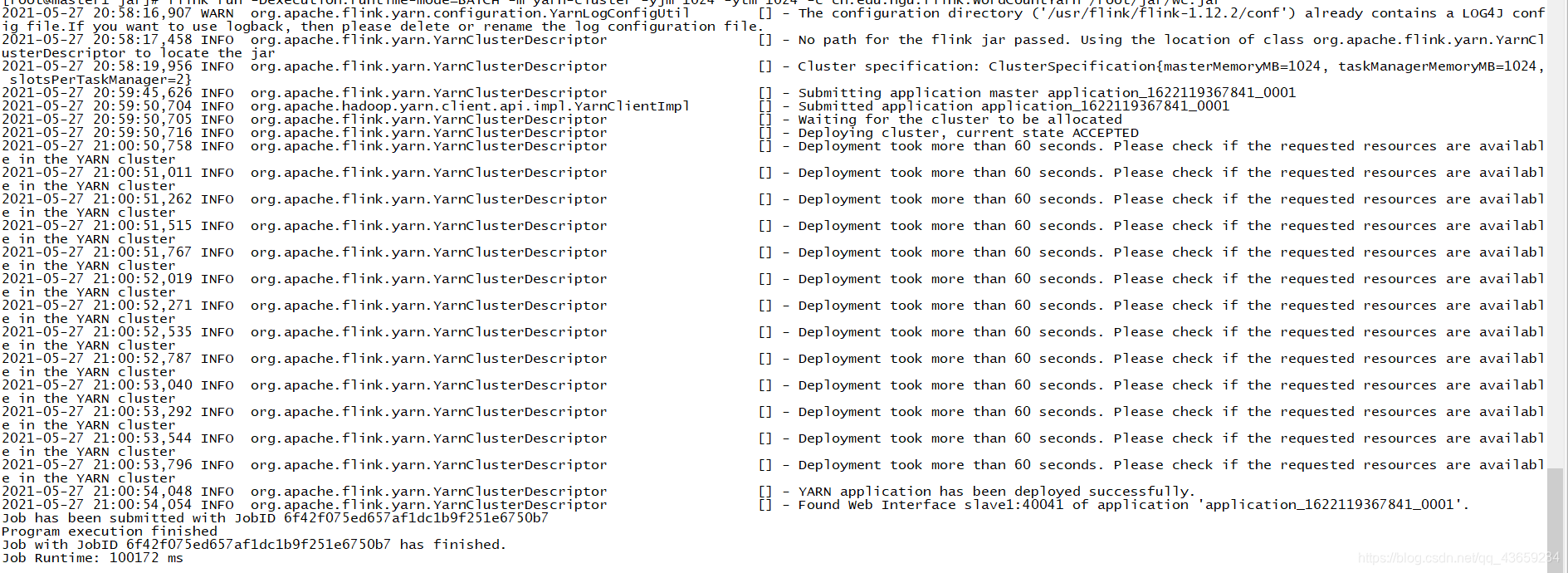
yarn UI查看

hdfs查看产生的文件

目前dataset基本上已经被抛弃了,目前基本使用datastream
原文链接:https://blog.csdn.net/qq_43659234/article/details/116786315
所属网站分类: 技术文章 > 博客
作者:以天使的名义
链接:http://www.javaheidong.com/blog/article/207194/1f467d661314929dc769/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力