

ElasticSearch的堆内存设置与优化
发布于2021-05-29 20:48 阅读(810) 评论(0) 点赞(4) 收藏(1)
Elasticsearch默认安装后设置的堆大小是1GB,对于生产环境来说,这个配置太小了。生产环境需要根据实际需求,调整JVM的堆大小。
1. 启动时脚本调用顺序
es的启动脚本是bin下的elasticsearch, 在启动时,脚本调用顺序如下: 【以elasticsearch 7.2的脚本为例】
-
source elasticsearch-env, 设置ES_HOME、ES_CLASSPATH、ES_PATH_CONF、ES_DISTRIBUTION_FLAVOR等变量的值,并配置HOSTNAME的环境变量,通过 org.elasticsearch.tools.java_version_checker.JavaVersionChecker检查JAVA 版本是否符合要求
-
如果ES_TMPDIR目录不存在,则通过org.elasticsearch.tools.launchers.TempDirectory设置ES_TMPDIR的目录
-
通过org.elasticsearch.tools.launchers.JvmOptionsParser读取"$ES_PATH_CONF"/jvm.options的JVM配置,设置JVM_OPTIONS变量
-
将JVM_OPTIONS中全部${ES_TMPDIR}变量替换为ES_TMPDIR的值,然后赋值给ES_JAVA_OPTS变量
-
通过exec启动JVM进程,如果启动时指定的 -d 或 --daemonize参数,则以后台方式启动,否则前台脚本
2. 修改堆大小方式
通过启动时脚本调用顺序的分析,如果修改堆大小,则只需要修改jvm.options文件中的-xms,-xmx两个参数即可
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g
注意:需要确保Xmx和Xms的大小一致,是为了避免频繁扩容和GC释放堆内存造成的系统开销/压力
2.1. Xms和Xmx参数定义
在启动Java应用程序时,我们通常可以通过参数Xms和Xmx来配置JVM的堆信息。不配置虽然会有默认值,但如果受硬件所限或需对JVM进行调优,则需要根据情况指定这两个参数的值。
-Xms:堆内存的最小Heap值,默认为物理内存的1/64,但小于1G。默认当空余堆内存大于指定阈值时,JVM会减小heap的大小到-Xms指定的大小。
-Xmx:堆内存的最大Heap值,默认为物理内存的1/4。默认当空余堆内存小于指定阈值时,JVM会增大Heap到-Xmx指定的大小。
3. 堆大小设置的坑
Elasticsearch针对内存分配的建议如下图:
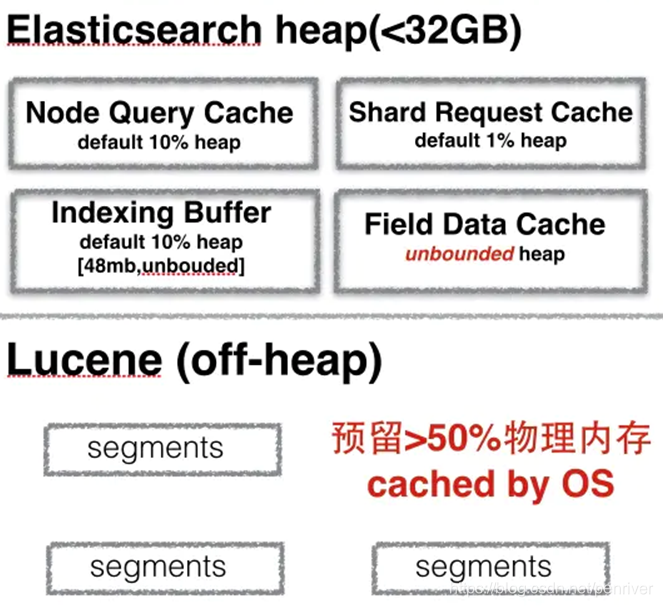
3.1. 不能超过总内存的50%
Xms和Xmx的大小不能超过总内存的50%。
因为除了JVM堆之外,Elasticsearch还需要内存,例如,Elasticsearch使用堆外缓冲区来实现高效的网络通信,并依赖于操作系统的文件系统缓存来实现对文件的高效访问。
JVM本身也需要一些内存。对于Elasticsearch来说,使用的内存通常会超过Xmx设置配置的限制。
elasticsearch底层使用Lucene存储数据。Lucene利用底层操作系统来缓存内存中的数据结构。 Lucene段(segment)存储在单个文件中。因为段是一成不变的,所以这些文件永远不会改变。这使得它们非常容易缓存,并且底层操作系统将热段(hot segments)保留在内存中以便提供更快地访问。这些段包括倒排索引(用于全文搜索)和文档值(用于聚合)。
Lucene的性能依赖于与操作系统的这种交互。但是如果你把所有可用的内存都给了Elasticsearch的堆,那么Lucene就不会有任何剩余的内存。这会严重影响性能。
标准建议是将可用内存的50%提供给Elasticsearch堆,而将其他50%留给Lucene.
如果不需要字符串字段上做聚合操作(例如,您不需要fielddata),则可以考虑进一步降低堆。
3.2. 不能超过oops的阈值
Xms和Xmx的大小不能超过32gb,这是压缩普通对象指针【oops】的近似阈值。要验证您是否低于阈值,请检查elasticsearch.logs中是否存在如下日志:
heap size [1.9gb], compressed ordinary object pointers [true]
Xms和Xmx的大小不能超过基于0的压缩oops的阈值。确切的阈值在不同的系统上有所不同,但在大多数系统上26GB是安全的,在某些系统上可能高达30GB。您可以通过启动Elasticsearch和JVM选项-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompressedOopsMode并检查elasticsearch.logs 来验证您是否低于这个阈值。
以下日志表明:zero-based compressed oops 被激活
heap address: 0x000000011be00000, size: 27648 MB, zero based Compressed Oops
以下日志表明:zero-based compressed oops 未被激活,则设置的堆大小超过了oops的阀值,需要调小一些。
heap address: 0x0000000118400000, size: 28672 MB, Compressed Oops with base: 0x00000001183ff000
详见官方文档:
4. 引申内容
4.1. 为什么不能超过oops的阀值
在Java中,所有对象都分配在堆上并由指针引用。普通对象指针(OOP)指向这些对象,传统上它们是CPU本地字的大小:32位或64位,取决于处理器。
压缩oop的概念是由32位和64位体系结构之间的差异引起的,在6u23之前的JDK中,默认情况下未激活它,在32位操作系统下,也没有必要激活。在jdk 8中默认开启动,
通过-XX:+UseCompressedOops 或 -XX:-UseCompressedOops 进行开启或关闭压缩oops
在32位系统中,内存地址宽度为32位(因此称为名称),这意味着可寻址内存的总量为2 ^ 32或4 GB RAM
对于64位系统,堆大小可能会变得更大,但是64位指针的开销意味着仅仅因为指针较大而存在更多的浪费空间。并且比浪费的空间更糟糕,当在主存储器和各种缓存(LLC,L1等等)之间移动值时,较大的指针消耗更多的带宽, 造成更频繁的GC开销、并降低CPU缓存命中率【64位对象引用增大了,CPU能缓存的oop将会更少,从而降低了CPU缓存的效率】
Java使用称为压缩oops的技巧来解决这个问题。压缩的oop通过在64位环境中使用32位类指针来帮助您保留一些内存,前提是您的堆大小不会大于32 GB(不同操作系统可能不同)。
这些指针不是指向内存中的确切字节位置,指针引用对象偏移量。
注意:一旦你穿越了压缩oops的阀值,指针就会切换回普通的对象指针。每个指针的大小增加,使用更多的CPU、内存、带宽,并且实际上会丢失内存。
即使你有足够的内存空间,尽量避免跨越32GB的堆边界。否则会导致浪费了内存,降低了CPU的性能,并使GC在大堆中挣扎
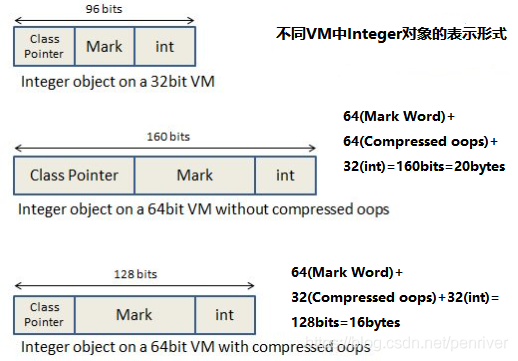
注意:由于JVM内存分配需要根据字宽进行对齐,对于64位JVM,字宽为8个字节。因此,一个Integer实际占用24bytes,即192bits。
4.2. 压缩的oop如何实现
JVM的实现方式是,不再保存所有引用,而是每隔8个字节保存一个引用。例如,原来保存每个引用0、1、2...,现在只保存0、8、16...。因此,指针压缩后,并不是所有引用都保存在堆中,而是以8个字节为间隔保存引用。
在实现上,堆中的引用其实还是按照0x0、0x1、0x2...进行存储。只不过当引用被存入64位的寄存器时,JVM将其左移3位(相当于末尾添加3个0),例如0x0、0x1、0x2...分别被转换为0x0、0x8、0x10。而当从寄存器读出时,JVM又可以右移3位,丢弃末尾的0。(oop在堆中是32位,在寄存器中是35位,2的35次方=32G。也就是说,使用32位,来达到35位oop所能引用的堆内存空间)
压缩的oop背后的技巧是内存的字节寻址和字寻址之间的区别。 使用字节寻址,您可以访问内存中的每个字节,但每个字节也需要一个唯一的地址。 在32位环境中,这会将您限制为2 ^ 32字节的内存(4GB内存)。 在字寻址中,您仍然具有相同数量的可寻址存储块,但是此存储块是一个字而不是一个字节。 在64位计算机中,一个字为8个字节。 这为JVM提供了三个零位。 Java通过转移这些位来利用它们,以扩展可寻址内存并实现压缩的oop。
在JVM中(不管是32位还是64位),对象已经按8字节边界对齐了。对于大部分处理器,这种对齐方案都是最优的。所以,使用压缩的oop并不会带来什么损失,反而提升了性能。
虽然理论上压缩的oop可寻址内存的总量为2 ^ 35即32GB, 但在不同的系统上有所不同,通常26GB是安全的。
原文链接:https://blog.csdn.net/penriver/article/details/117330593
所属网站分类: 技术文章 > 博客
作者:怎么没有鱼儿上钩呢
链接:http://www.javaheidong.com/blog/article/207227/f15ba297565b4b81caf4/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力