

Java面试:2021.05.18
发布于2021-05-29 20:04 阅读(910) 评论(0) 点赞(26) 收藏(2)
1、讲一下你对线程池的理解。
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
而本文描述线程池是JDK中提供的ThreadPoolExecutor类。
当然,使用线程池可以带来一系列好处:
-
降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
-
提高响应速度:任务到达时,无需等待线程创建即可立即执行。
-
提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
-
提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
2、线程池解决了什么问题?
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
-
频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大。
-
对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险。
-
系统无法合理管理内部的资源分布,会降低系统的稳定性。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。
Pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management.——wikipedia
“池化”思想不仅仅能应用在计算机领域,在金融、设备、人员管理、工作管理等领域也有相关的应用。
在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。通过共享资源,使用户在低投入中获益。除去线程池,还有其他比较典型的几种使用策略包括:
-
内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
-
连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
-
实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
3、如何判断GC是否存在问题?
评判 GC 的两个核心指标:
-
延迟(Latency): 也可以理解为最大停顿时间,即垃圾收集过程中一次 STW 的最长时间,越短越好,一定程度上可以接受频次的增大,GC 技术的主要发展方向。
-
吞吐量(Throughput): 应用系统的生命周期内,由于 GC 线程会占用 Mutator 当前可用的 CPU 时钟周期,吞吐量即为 Mutator 有效花费的时间占系统总运行时间的百分比,例如系统运行了 100 min,GC 耗时 1 min,则系统吞吐量为 99%,吞吐量优先的收集器可以接受较长的停顿。
目前各大互联网公司的系统基本都更追求低延时,避免一次 GC 停顿的时间过长对用户体验造成损失,衡量指标需要结合一下应用服务的 SLA,主要如下两点来判断:

简而言之,即为一次停顿的时间不超过应用服务的 TP9999,GC 的吞吐量不小于 99.99%。举个例子,假设某个服务 A 的 TP9999 为 80 ms,平均 GC 停顿为 30 ms,那么该服务的最大停顿时间最好不要超过 80 ms,GC 频次控制在 5 min 以上一次。如果满足不了,那就需要调优或者通过更多资源来进行并联冗余。(大家可以先停下来,看看监控平台上面的 gc.meantime 分钟级别指标,如果超过了 6 ms 那单机 GC 吞吐量就达不到 4 个 9 了。)
备注:除了这两个指标之外还有 Footprint(资源量大小测量)、反应速度等指标,互联网这种实时系统追求低延迟,而很多嵌入式系统则追求 Footprint。
4、如何判断是不是由GC引发的问题?
-
时序分析: 先发生的事件是根因的概率更大,通过监控手段分析各个指标的异常时间点,还原事件时间线,如先观察到 CPU 负载高(要有足够的时间 Gap),那么整个问题影响链就可能是:CPU 负载高 -> 慢查询增多 -> GC 耗时增大 -> 线程Block增多 -> RT 上涨。
-
概率分析: 使用统计概率学,结合历史问题的经验进行推断,由近到远按类型分析,如过往慢查的问题比较多,那么整个问题影响链就可能是:慢查询增多 -> GC 耗时增大 -> CPU 负载高 -> 线程 Block 增多 -> RT上涨。
-
实验分析: 通过故障演练等方式对问题现场进行模拟,触发其中部分条件(一个或多个),观察是否会发生问题,如只触发线程 Block 就会发生问题,那么整个问题影响链就可能是:线程Block增多 -> CPU 负载高 -> 慢查询增多 -> GC 耗时增大 -> RT 上涨。
-
反证分析: 对其中某一表象进行反证分析,即判断表象的发不发生跟结果是否有相关性,例如我们从整个集群的角度观察到某些节点慢查和 CPU 都正常,但也出了问题,那么整个问题影响链就可能是:GC 耗时增大 -> 线程 Block 增多 -> RT 上涨。
不同的根因,后续的分析方法是完全不同的。如果是 CPU 负载高那可能需要用火焰图看下热点、如果是慢查询增多那可能需要看下 DB 情况、如果是线程 Block 引起那可能需要看下锁竞争的情况,最后如果各个表象证明都没有问题,那可能 GC 确实存在问题,可以继续分析 GC 问题了。
5、GC问题的解决方案。
5.1 处理流程(SOP)
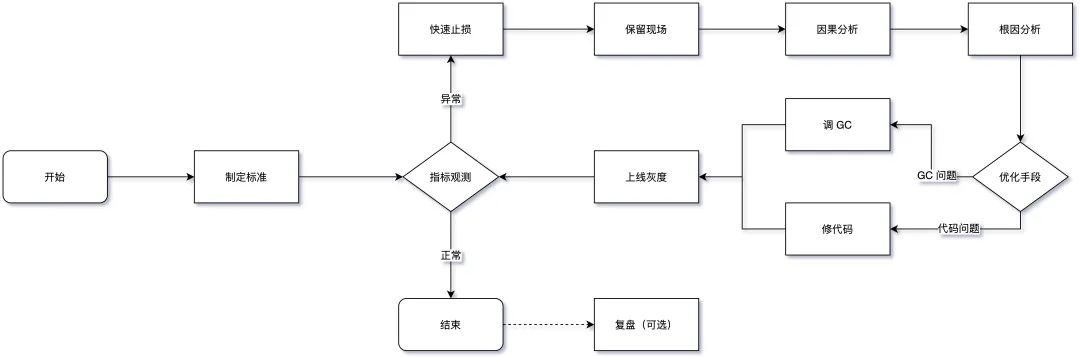
下图为整体 GC 问题普适的处理流程,重点的地方下面会单独标注,其他的基本都是标准处理流程,此处不再赘述,最后在整个问题都处理完之后有条件的话建议做一下复盘。
-
制定标准: 这块内容其实非常重要,但大部分系统都是缺失的,笔者过往面试的同学中只有不到一成的同学能给出自己的系统 GC 标准到底什么样,其他的都是用的统一指标模板,缺少预见性,具体指标制定可以参考 3.1 中的内容,需要结合应用系统的 TP9999 时间和延迟、吞吐量等设定具体的指标,而不是被问题驱动。
-
保留现场: 目前线上服务基本都是分布式服务,某个节点发生问题后,如果条件允许一定不要直接操作重启、回滚等动作恢复,优先通过摘掉流量的方式来恢复,这样我们可以将堆、栈、GC 日志等关键信息保留下来,不然错过了定位根因的时机,后续解决难度将大大增加。当然除了这些,应用日志、中间件日志、内核日志、各种 Metrics 指标等对问题分析也有很大帮助。
-
因果分析: 判断 GC 异常与其他系统指标异常的因果关系,可以参考笔者在 3.2 中介绍的时序分析、概率分析、实验分析、反证分析等 4 种因果分析法,避免在排查过程中走入误区。
-
根因分析: 确实是 GC 的问题后,可以借助上文提到的工具并通过 5 why 根因分析法以及跟第三节中的九种常见的场景进行逐一匹配,或者直接参考下文的根因鱼骨图,找出问题发生根因,最后再选择优化手段。
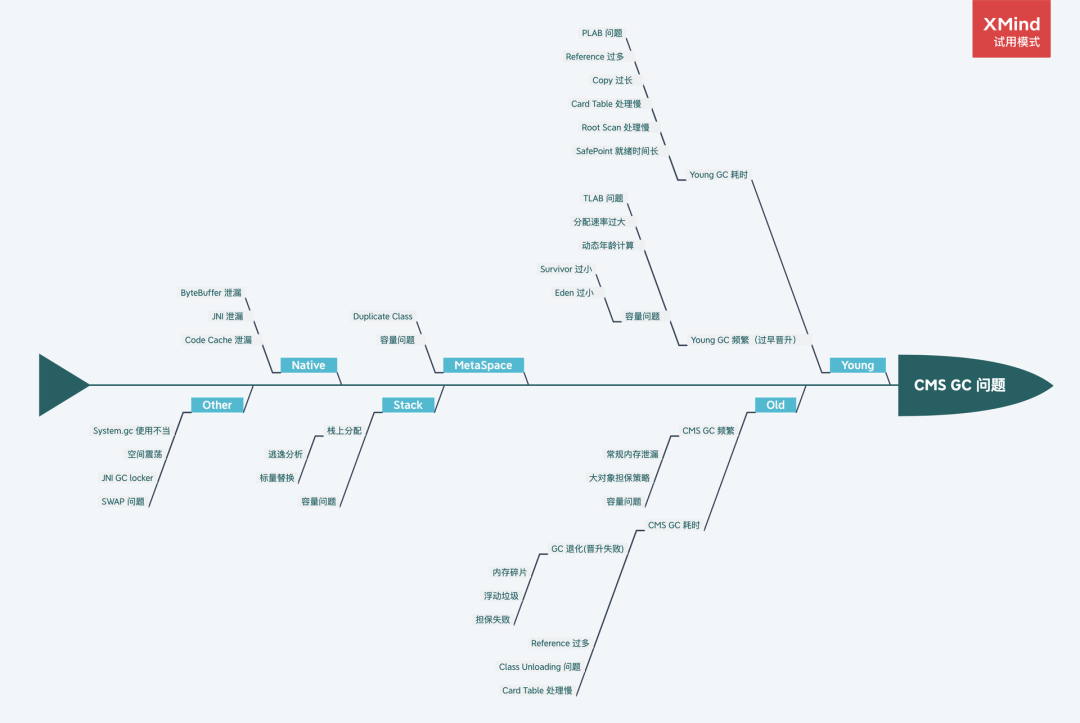
5.2 根因鱼骨图
送上一张问题根因鱼骨图,一般情况下我们在处理一个 GC 问题时,只要能定位到问题的“病灶”,有的放矢,其实就相当于解决了 80%,如果在某些场景下不太好定位,大家可以借助这种根因分析图通过排除法去定位。
5.3 调优建议
-
Trade Off: 与 CAP 注定要缺一角一样,GC 优化要在延迟(Latency)、吞吐量(Throughput)、容量(Capacity)三者之间进行权衡。
-
最终手段: GC 发生问题不是一定要对 JVM 的 GC 参数进行调优,大部分情况下是通过 GC 的情况找出一些业务问题,切记上来就对 GC 参数进行调整,当然有明确配置错误的场景除外。
-
控制变量: 控制变量法是在蒙特卡洛(Monte Carlo)方法中用于减少方差的一种技术方法,我们调优的时候尽量也要使用,每次调优过程尽可能只调整一个变量。
-
善用搜索: 理论上 99.99% 的 GC 问题基本都被遇到了,我们要学会使用搜索引擎的高级技巧,重点关注 StackOverFlow、Github 上的 Issue、以及各种论坛博客,先看看其他人是怎么解决的,会让解决问题事半功倍。能看到这篇文章,你的搜索能力基本过关了~
-
调优重点: 总体上来讲,我们开发的过程中遇到的问题类型也基本都符合正态分布,太简单或太复杂的基本遇到的概率很低,笔者这里将中间最重要的三个场景添加了“*”标识,希望阅读完本文之后可以观察下自己负责的系统,是否存在上述问题。
-
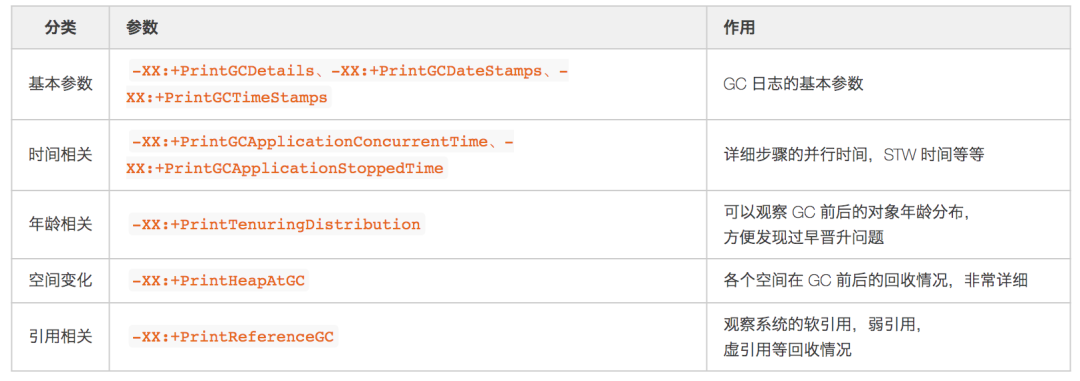
GC 参数: 如果堆、栈确实无法第一时间保留,一定要保留 GC 日志,这样我们最起码可以看到 GC Cause,有一个大概的排查方向。关于 GC 日志相关参数,最基本的
-XX:+HeapDumpOnOutOfMemoryError等一些参数就不再提了,笔者建议添加以下参数,可以提高我们分析问题的效率。
-
其他建议: 上文场景中没有提到,但是对 GC 性能也有提升的一些建议。
-
主动式 GC: 也有另开生面的做法,通过监控手段监控观测 Old 区的使用情况,即将到达阈值时将应用服务摘掉流量,手动触发一次 Major GC,减少 CMS GC 带来的停顿,但随之系统的健壮性也会减少,如非必要不建议引入。
-
禁用偏向锁: 偏向锁在只有一个线程使用到该锁的时候效率很高,但是在竞争激烈情况会升级成轻量级锁,此时就需要先消除偏向锁,这个过程是 STW 的。如果每个同步资源都走这个升级过程,开销会非常大,所以在已知并发激烈的前提下,一般会禁用偏向锁
-XX:-UseBiasedLocking来提高性能。 -
虚拟内存: 启动初期有些操作系统(例如 Linux)并没有真正分配物理内存给 JVM ,而是在虚拟内存中分配,使用的时候才会在物理内存中分配内存页,这样也会导致 GC 时间较长。这种情况可以添加
-XX:+AlwaysPreTouch参数,让 VM 在 commit 内存时跑个循环来强制保证申请的内存真的 commit,避免运行时触发缺页异常。在一些大内存的场景下,有时候能将前几次的 GC 时间降一个数量级,但是添加这个参数后,启动的过程可能会变慢。
-
6、项目中为什么需要用到设计模式?
营销业务的特点
营销业务与交易等其他模式相对稳定的业务的区别在于,营销需求会随着市场、用户、环境的不断变化而进行调整。也正是因此,外卖营销技术团队选择了DDD进行领域建模,并在适用的场景下,用设计模式在代码工程的层面上实践和反映了领域模型。以此来做到在支持业务变化的同时,让领域和代码模型健康演进,避免模型腐化。
理解设计模式
软件设计模式(Design pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码,让代码更容易被他人理解,保证代码可靠性,程序的重用性。可以理解为:“世上本来没有设计模式,用的人多了,便总结出了一套设计模式。”
设计模式原则
面向对象的设计模式有七大基本原则:
-
开闭原则(Open Closed Principle,OCP)
-
单一职责原则(Single Responsibility Principle, SRP)
-
里氏代换原则(Liskov Substitution Principle,LSP)
-
依赖倒转原则(Dependency Inversion Principle,DIP)
-
接口隔离原则(Interface Segregation Principle,ISP)
-
合成/聚合复用原则(Composite/Aggregate Reuse Principle,CARP)
-
最少知识原则(Least Knowledge Principle,LKP)或者迪米特法则(Law of Demeter,LOD)
简单理解就是:开闭原则是总纲,它指导我们要对扩展开放,对修改关闭;单一职责原则指导我们实现类要职责单一;里氏替换原则指导我们不要破坏继承体系;依赖倒置原则指导我们要面向接口编程;接口隔离原则指导我们在设计接口的时候要精简单一;迪米特法则指导我们要降低耦合。
设计模式就是通过这七个原则,来指导我们如何做一个好的设计。但是设计模式不是一套“奇技淫巧”,它是一套方法论,一种高内聚、低耦合的设计思想。我们可以在此基础上自由的发挥,甚至设计出自己的一套设计模式。
当然,学习设计模式或者是在工程中实践设计模式,必须深入到某一个特定的业务场景中去,再结合对业务场景的理解和领域模型的建立,才能体会到设计模式思想的精髓。如果脱离具体的业务逻辑去学习或者使用设计模式,那是极其空洞的。接下来我们将通过外卖营销业务的实践,来探讨如何用设计模式来实现可重用、易维护的代码。
7、设计模式在项目中的体现(应用+实践)?
7.1 “邀请下单”业务中设计模式的实践
7.1.1 业务简介
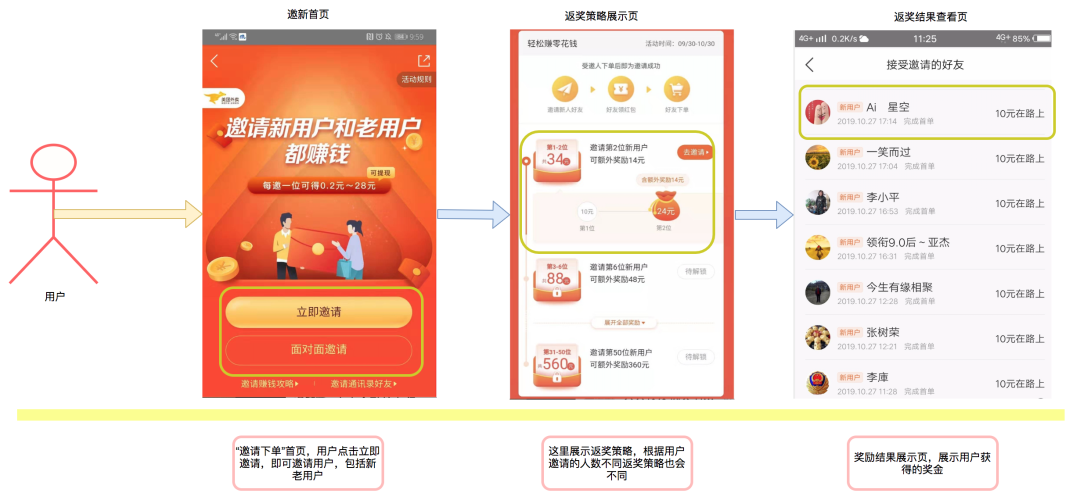
“邀请下单”是美团外卖用户邀请其他用户下单后给予奖励的平台。即用户A邀请用户B,并且用户B在美团下单后,给予用户A一定的现金奖励(以下简称返奖)。同时为了协调成本与收益的关系,返奖会有多个计算策略。邀请下单后台主要涉及两个技术要点:
-
返奖金额的计算,涉及到不同的计算规则。
-
从邀请开始到返奖结束的整个流程。
7.1.2 返奖规则与设计模式实践
业务建模
如图是返奖规则计算的业务逻辑视图:
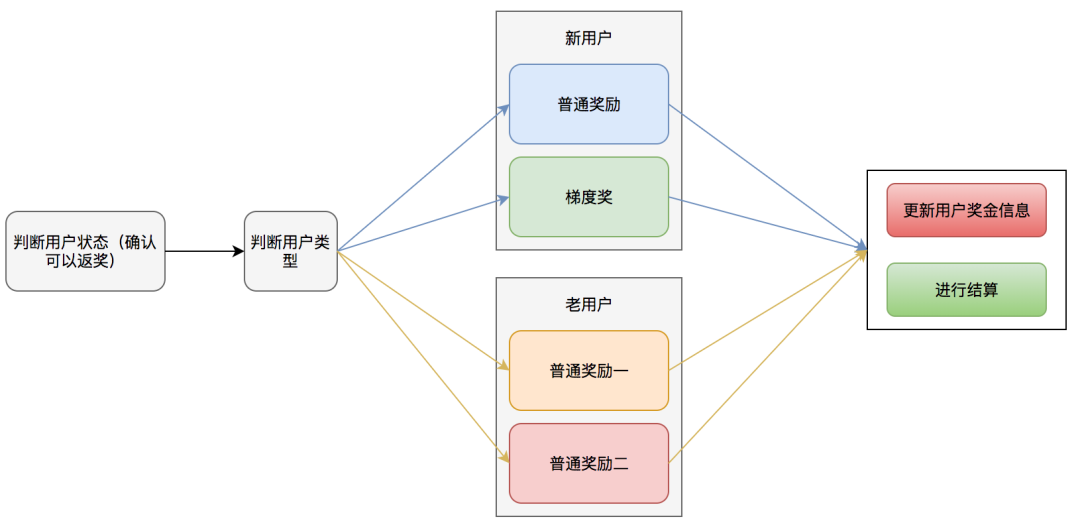
从这份业务逻辑图中可以看到返奖金额计算的规则。首先要根据用户状态确定用户是否满足返奖条件。如果满足返奖条件,则继续判断当前用户属于新用户还是老用户,从而给予不同的奖励方案。一共涉及以下几种不同的奖励方案:
新用户
-
普通奖励(给予固定金额的奖励)
-
梯度奖(根据用户邀请的人数给予不同的奖励金额,邀请的人越多,奖励金额越多)
老用户
-
根据老用户的用户属性来计算返奖金额。为了评估不同的邀新效果,老用户返奖会存在多种返奖机制。
计算完奖励金额以后,还需要更新用户的奖金信息,以及通知结算服务对用户的金额进行结算。这两个模块对于所有的奖励来说都是一样的。
可以看到,无论是何种用户,对于整体返奖流程是不变的,唯一变化的是返奖规则。此处,我们可参考开闭原则,对于返奖流程保持封闭,对于可能扩展的返奖规则进行开放。我们将返奖规则抽象为返奖策略,即针对不同用户类型的不同返奖方案,我们视为不同的返奖策略,不同的返奖策略会产生不同的返奖金额结果。
在我们的领域模型里,返奖策略是一个值对象,我们通过工厂的方式生产针对不同用户的奖励策略值对象。下文我们将介绍以上领域模型的工程实现,即工厂模式和策略模式的实际应用。
模式:工厂模式
工厂模式又细分为工厂方法模式和抽象工厂模式,本文主要介绍工厂方法模式。
模式定义:定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法是一个类的实例化延迟到其子类。
工厂模式通用类图如下:
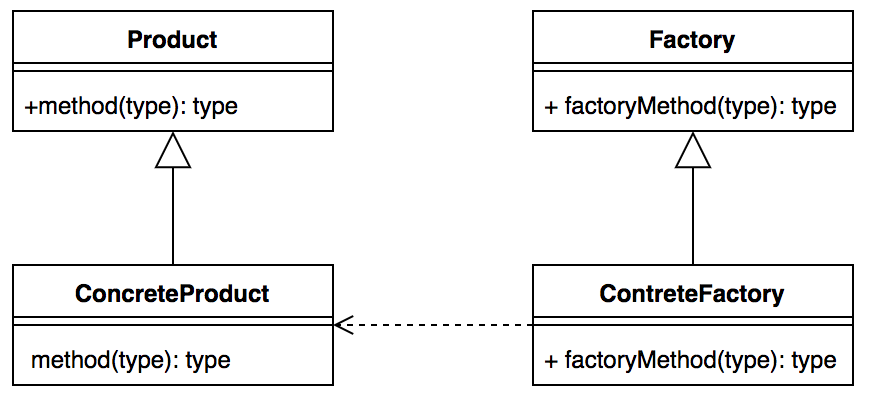
我们通过一段较为通用的代码来解释如何使用工厂模式:
- //抽象的产品
- public abstract class Product {
- public abstract void method();
- }
- //定义一个具体的产品 (可以定义多个具体的产品)
- class ProductA extends Product {
- @Override
- public void method() {} //具体的执行逻辑
- }
- //抽象的工厂
- abstract class Factory<T> {
- abstract Product createProduct(Class<T> c);
- }
- //具体的工厂可以生产出相应的产品
- class FactoryA extends Factory{
- @Override
- Product createProduct(Class c) {
- Product product = (Product) Class.forName(c.getName()).newInstance();
- return product;
- }
- }
模式:策略模式
模式定义:定义一系列算法,将每个算法都封装起来,并且它们可以互换。策略模式是一种对象行为模式。
策略模式通用类图如下:
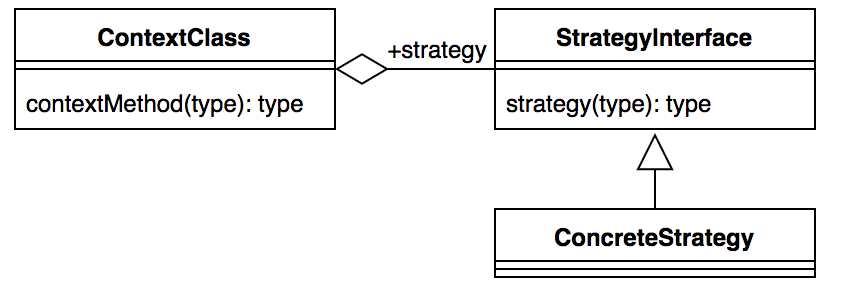
我们通过一段比较通用的代码来解释怎么使用策略模式:
- //定义一个策略接口
- public interface Strategy {
- void strategyImplementation();
- }
-
- //具体的策略实现(可以定义多个具体的策略实现)
- public class StrategyA implements Strategy{
- @Override
- public void strategyImplementation() {
- System.out.println("正在执行策略A");
- }
- }
-
- //封装策略,屏蔽高层模块对策略、算法的直接访问,屏蔽可能存在的策略变化
- public class Context {
- private Strategy strategy = null;
-
- public Context(Strategy strategy) {
- this.strategy = strategy;
- }
-
- public void doStrategy() {
- strategy.strategyImplementation();
- }
- }
工程实践
通过上文介绍的返奖业务模型,我们可以看到返奖的主流程就是选择不同的返奖策略的过程,每个返奖策略都包括返奖金额计算、更新用户奖金信息、以及结算这三个步骤。我们可以使用工厂模式生产出不同的策略,同时使用策略模式来进行不同的策略执行。首先确定我们需要生成出n种不同的返奖策略,其编码如下:
- //抽象策略
- public abstract class RewardStrategy {
- public abstract void reward(long userId);
-
- public void insertRewardAndSettlement(long userId, int reward) {} ; //更新用户信息以及结算
- }
- //新用户返奖具体策略A
- public class newUserRewardStrategyA extends RewardStrategy {
- @Override
- public void reward(long userId) {} //具体的计算逻辑,...
- }
-
- //老用户返奖具体策略A
- public class OldUserRewardStrategyA extends RewardStrategy {
- @Override
- public void reward(long userId) {} //具体的计算逻辑,...
- }
-
- //抽象工厂
- public abstract class StrategyFactory<T> {
- abstract RewardStrategy createStrategy(Class<T> c);
- }
-
- //具体工厂创建具体的策略
- public class FactorRewardStrategyFactory extends StrategyFactory {
- @Override
- RewardStrategy createStrategy(Class c) {
- RewardStrategy product = null;
- try {
- product = (RewardStrategy) Class.forName(c.getName()).newInstance();
- } catch (Exception e) {}
- return product;
- }
- }
通过工厂模式生产出具体的策略之后,根据我们之前的介绍,很容易就可以想到使用策略模式来执行我们的策略。具体代码如下:
- public class RewardContext {
- private RewardStrategy strategy;
-
- public RewardContext(RewardStrategy strategy) {
- this.strategy = strategy;
- }
-
- public void doStrategy(long userId) {
- int rewardMoney = strategy.reward(userId);
- insertRewardAndSettlement(long userId, int reward) {
- insertReward(userId, rewardMoney);
- settlement(userId);
- }
- }
- }
接下来我们将工厂模式和策略模式结合在一起,就完成了整个返奖的过程:
- public class InviteRewardImpl {
- //返奖主流程
- public void sendReward(long userId) {
- FactorRewardStrategyFactory strategyFactory = new FactorRewardStrategyFactory(); //创建工厂
- Invitee invitee = getInviteeByUserId(userId); //根据用户id查询用户信息
- if (invitee.userType == UserTypeEnum.NEW_USER) { //新用户返奖策略
- NewUserBasicReward newUserBasicReward = (NewUserBasicReward) strategyFactory.createStrategy(NewUserBasicReward.class);
- RewardContext rewardContext = new RewardContext(newUserBasicReward);
- rewardContext.doStrategy(userId); //执行返奖策略
- }if(invitee.userType == UserTypeEnum.OLD_USER){} //老用户返奖策略,...
- }
- }
工厂方法模式帮助我们直接产生一个具体的策略对象,策略模式帮助我们保证这些策略对象可以自由地切换而不需要改动其他逻辑,从而达到解耦的目的。通过这两个模式的组合,当我们系统需要增加一种返奖策略时,只需要实现RewardStrategy接口即可,无需考虑其他的改动。当我们需要改变策略时,只要修改策略的类名即可。不仅增强了系统的可扩展性,避免了大量的条件判断,而且从真正意义上达到了高内聚、低耦合的目的。
7.1.3 返奖流程与设计模式实践
业务建模
当受邀人在接受邀请人的邀请并且下单后,返奖后台接收到受邀人的下单记录,此时邀请人也进入返奖流程。首先我们订阅用户订单消息并对订单进行返奖规则校验。例如,是否使用红包下单,是否在红包有效期内下单,订单是否满足一定的优惠金额等等条件。当满足这些条件以后,我们将订单信息放入延迟队列中进行后续处理。经过T+N天之后处理该延迟消息,判断用户是否对该订单进行了退款,如果未退款,对用户进行返奖。若返奖失败,后台还有返奖补偿流程,再次进行返奖。其流程如下图所示:
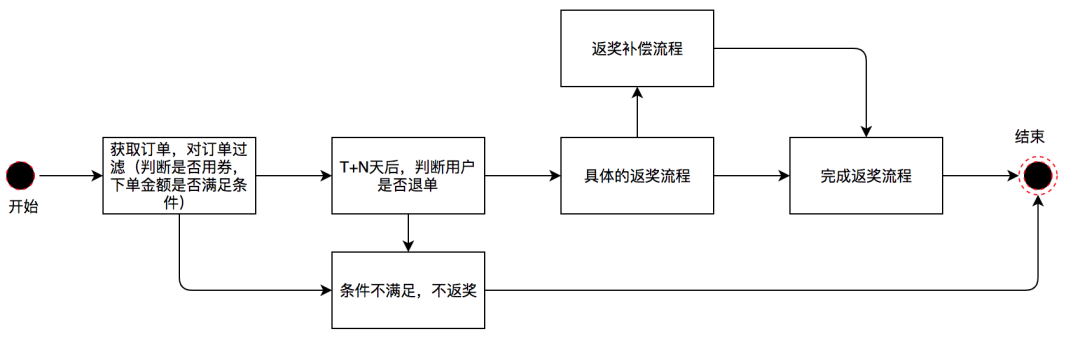
我们对上述业务流程进行领域建模:
-
在接收到订单消息后,用户进入待校验状态;
-
在校验后,若校验通过,用户进入预返奖状态,并放入延迟队列。若校验未通过,用户进入不返奖状态,结束流程;
-
T+N天后,处理延迟消息,若用户未退款,进入待返奖状态。若用户退款,进入失败状态,结束流程;
-
执行返奖,若返奖成功,进入完成状态,结束流程。若返奖不成功,进入待补偿状态;
-
待补偿状态的用户会由任务定期触发补偿机制,直至返奖成功,进入完成状态,保障流程结束。
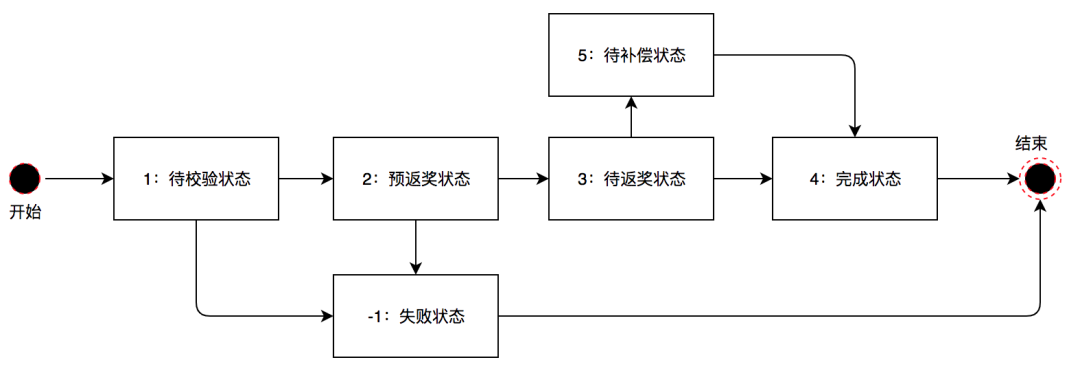
可以看到,我们通过建模将返奖流程的多个步骤映射为系统的状态。对于系统状态的表述,DDD中常用到的概念是领域事件,另外也提及过事件溯源的实践方案。当然,在设计模式中,也有一种能够表述系统状态的代码模型,那就是状态模式。在邀请下单系统中,我们的主要流程是返奖。对于返奖,每一个状态要进行的动作和操作都是不同的。因此,使用状态模式,能够帮助我们对系统状态以及状态间的流转进行统一的管理和扩展。
模式:状态模式
模式定义:当一个对象内在状态改变时允许其改变行为,这个对象看起来像改变了其类。
状态模式的通用类图如下图所示:
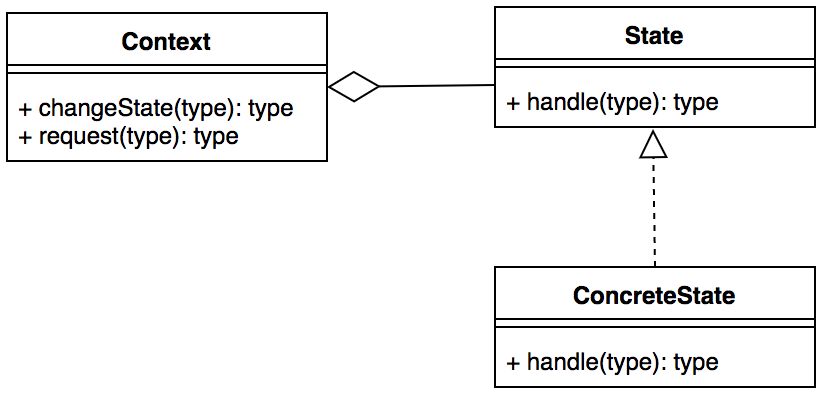
对比策略模式的类型会发现和状态模式的类图很类似,但实际上有很大的区别,具体体现在concrete class上。策略模式通过Context产生唯一一个ConcreteStrategy作用于代码中,而状态模式则是通过context组织多个ConcreteState形成一个状态转换图来实现业务逻辑。接下来,我们通过一段通用代码来解释怎么使用状态模式:
- //定义一个抽象的状态类
- public abstract class State {
- Context context;
- public void setContext(Context context) {
- this.context = context;
- }
- public abstract void handle1();
- public abstract void handle2();
- }
- //定义状态A
- public class ConcreteStateA extends State {
- @Override
- public void handle1() {} //本状态下必须要处理的事情
-
- @Override
- public void handle2() {
- super.context.setCurrentState(Context.contreteStateB); //切换到状态B
- super.context.handle2(); //执行状态B的任务
- }
- }
- //定义状态B
- public class ConcreteStateB extends State {
- @Override
- public void handle2() {} //本状态下必须要处理的事情,...
-
- @Override
- public void handle1() {
- super.context.setCurrentState(Context.contreteStateA); //切换到状态A
- super.context.handle1(); //执行状态A的任务
- }
- }
- //定义一个上下文管理环境
- public class Context {
- public final static ConcreteStateA contreteStateA = new ConcreteStateA();
- public final static ConcreteStateB contreteStateB = new ConcreteStateB();
-
- private State CurrentState;
- public State getCurrentState() {return CurrentState;}
-
- public void setCurrentState(State currentState) {
- this.CurrentState = currentState;
- this.CurrentState.setContext(this);
- }
-
- public void handle1() {this.CurrentState.handle1();}
- public void handle2() {this.CurrentState.handle2();}
- }
- //定义client执行
- public class client {
- public static void main(String[] args) {
- Context context = new Context();
- context.setCurrentState(new ContreteStateA());
- context.handle1();
- context.handle2();
- }
- }
工程实践
通过前文对状态模式的简介,我们可以看到当状态之间的转换在不是非常复杂的情况下,通用的状态模式存在大量的与状态无关的动作从而产生大量的无用代码。在我们的实践中,一个状态的下游不会涉及特别多的状态装换,所以我们简化了状态模式。当前的状态只负责当前状态要处理的事情,状态的流转则由第三方类负责。其实践代码如下:
- //返奖状态执行的上下文
- public class RewardStateContext {
-
- private RewardState rewardState;
-
- public void setRewardState(RewardState currentState) {this.rewardState = currentState;}
- public RewardState getRewardState() {return rewardState;}
- public void echo(RewardStateContext context, Request request) {
- rewardState.doReward(context, request);
- }
- }
-
- public abstract class RewardState {
- abstract void doReward(RewardStateContext context, Request request);
- }
-
- //待校验状态
- public class OrderCheckState extends RewardState {
- @Override
- public void doReward(RewardStateContext context, Request request) {
- orderCheck(context, request); //对进来的订单进行校验,判断是否用券,是否满足优惠条件等等
- }
- }
-
- //待补偿状态
- public class CompensateRewardState extends RewardState {
- @Override
- public void doReward(RewardStateContext context, Request request) {
- compensateReward(context, request); //返奖失败,需要对用户进行返奖补偿
- }
- }
-
- //预返奖状态,待返奖状态,成功状态,失败状态(此处逻辑省略)
- //..
-
- public class InviteRewardServiceImpl {
- public boolean sendRewardForInvtee(long userId, long orderId) {
- Request request = new Request(userId, orderId);
- RewardStateContext rewardContext = new RewardStateContext();
- rewardContext.setRewardState(new OrderCheckState());
- rewardContext.echo(rewardContext, request); //开始返奖,订单校验
- //此处的if-else逻辑只是为了表达状态的转换过程,并非实际的业务逻辑
- if (rewardContext.isResultFlag()) { //如果订单校验成功,进入预返奖状态
- rewardContext.setRewardState(new BeforeRewardCheckState());
- rewardContext.echo(rewardContext, request);
- } else {//如果订单校验失败,进入返奖失败流程,...
- rewardContext.setRewardState(new RewardFailedState());
- rewardContext.echo(rewardContext, request);
- return false;
- }
- if (rewardContext.isResultFlag()) {//预返奖检查成功,进入待返奖流程,...
- rewardContext.setRewardState(new SendRewardState());
- rewardContext.echo(rewardContext, request);
- } else { //如果预返奖检查失败,进入返奖失败流程,...
- rewardContext.setRewardState(new RewardFailedState());
- rewardContext.echo(rewardContext, request);
- return false;
- }
- if (rewardContext.isResultFlag()) { //返奖成功,进入返奖结束流程,...
- rewardContext.setRewardState(new RewardSuccessState());
- rewardContext.echo(rewardContext, request);
- } else { //返奖失败,进入返奖补偿阶段,...
- rewardContext.setRewardState(new CompensateRewardState());
- rewardContext.echo(rewardContext, request);
- }
- if (rewardContext.isResultFlag()) { //补偿成功,进入返奖完成阶段,...
- rewardContext.setRewardState(new RewardSuccessState());
- rewardContext.echo(rewardContext, request);
- } else { //补偿失败,仍然停留在当前态,直至补偿成功(或多次补偿失败后人工介入处理)
- rewardContext.setRewardState(new CompensateRewardState());
- rewardContext.echo(rewardContext, request);
- }
- return true;
- }
- }
状态模式的核心是封装,将状态以及状态转换逻辑封装到类的内部来实现,也很好的体现了“开闭原则”和“单一职责原则”。每一个状态都是一个子类,不管是修改还是增加状态,只需要修改或者增加一个子类即可。在我们的应用场景中,状态数量以及状态转换远比上述例子复杂,通过“状态模式”避免了大量的if-else代码,让我们的逻辑变得更加清晰。同时由于状态模式的良好的封装性以及遵循的设计原则,让我们在复杂的业务场景中,能够游刃有余地管理各个状态。
7.2 点评外卖投放系统中设计模式的实践
7.2.1 业务简介
继续举例,点评App的外卖频道中会预留多个资源位为营销使用,向用户展示一些比较精品美味的外卖食品,为了增加用户点外卖的意向。当用户点击点评首页的“美团外卖”入口时,资源位开始加载,会通过一些规则来筛选出合适的展示Banner。
![]()
7.2.2 设计模式实践
业务建模
对于投放业务,就是要在这些资源位中展示符合当前用户的资源。其流程如下图所示:
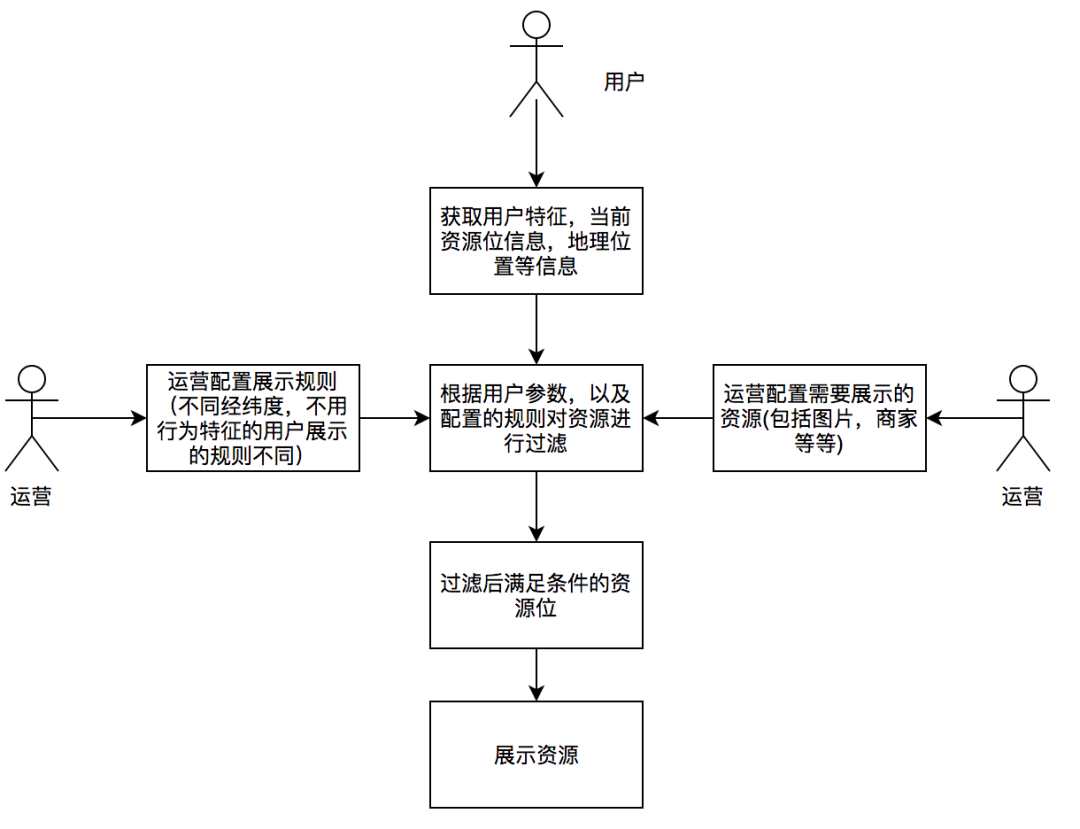
从流程中我们可以看到,首先运营人员会配置需要展示的资源,以及对资源进行过滤的规则。我们资源的过滤规则相对灵活多变,这里体现为三点:
-
过滤规则大部分可重用,但也会有扩展和变更。
-
不同资源位的过滤规则和过滤顺序是不同的。
-
同一个资源位由于业务所处的不同阶段,过滤规则可能不同。
过滤规则本身是一个个的值对象,我们通过领域服务的方式,操作这些规则值对象完成资源位的过滤逻辑。下图介绍了资源位在进行用户特征相关规则过滤时的过程:

为了实现过滤规则的解耦,对单个规则值对象的修改封闭,并对规则集合组成的过滤链条开放,我们在资源位过滤的领域服务中引入了责任链模式。
模式:责任链模式
模式定义:使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止。
责任链模式通用类图如下:
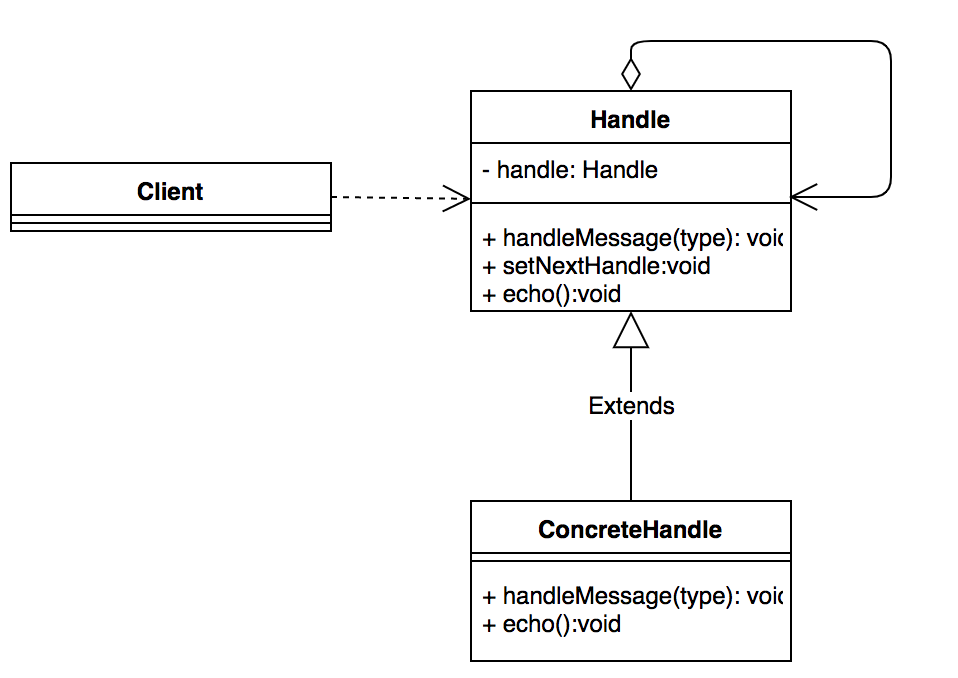
我们通过一段比较通用的代码来解释如何使用责任链模式:
- //定义一个抽象的handle
- public abstract class Handler {
- private Handler nextHandler; //指向下一个处理者
- private int level; //处理者能够处理的级别
-
- public Handler(int level) {
- this.level = level;
- }
-
- public void setNextHandler(Handler handler) {
- this.nextHandler = handler;
- }
-
- // 处理请求传递,注意final,子类不可重写
- public final void handleMessage(Request request) {
- if (level == request.getRequstLevel()) {
- this.echo(request);
- } else {
- if (this.nextHandler != null) {
- this.nextHandler.handleMessage(request);
- } else {
- System.out.println("已经到最尽头了");
- }
- }
- }
- // 抽象方法,子类实现
- public abstract void echo(Request request);
- }
-
- // 定义一个具体的handleA
- public class HandleRuleA extends Handler {
- public HandleRuleA(int level) {
- super(level);
- }
- @Override
- public void echo(Request request) {
- System.out.println("我是处理者1,我正在处理A规则");
- }
- }
-
- //定义一个具体的handleB
- public class HandleRuleB extends Handler {} //...
-
- //客户端实现
- class Client {
- public static void main(String[] args) {
- HandleRuleA handleRuleA = new HandleRuleA(1);
- HandleRuleB handleRuleB = new HandleRuleB(2);
- handleRuleA.setNextHandler(handleRuleB); //这是重点,将handleA和handleB串起来
- handleRuleA.echo(new Request());
- }
- }
工程实践
下面通过代码向大家展示如何实现这一套流程:
- //定义一个抽象的规则
- public abstract class BasicRule<CORE_ITEM, T extends RuleContext<CORE_ITEM>>{
- //有两个方法,evaluate用于判断是否经过规则执行,execute用于执行具体的规则内容。
- public abstract boolean evaluate(T context);
- public abstract void execute(T context) {
- }
-
- //定义所有的规则具体实现
- //规则1:判断服务可用性
- public class ServiceAvailableRule extends BasicRule<UserPortrait, UserPortraitRuleContext> {
- @Override
- public boolean evaluate(UserPortraitRuleContext context) {
- TakeawayUserPortraitBasicInfo basicInfo = context.getBasicInfo();
- if (basicInfo.isServiceFail()) {
- return false;
- }
- return true;
- }
-
- @Override
- public void execute(UserPortraitRuleContext context) {}
-
- }
- //规则2:判断当前用户属性是否符合当前资源位投放的用户属性要求
- public class UserGroupRule extends BasicRule<UserPortrait, UserPortraitRuleContext> {
- @Override
- public boolean evaluate(UserPortraitRuleContext context) {}
-
- @Override
- public void execute(UserPortraitRuleContext context) {
- UserPortrait userPortraitPO = context.getData();
- if(userPortraitPO.getUserGroup() == context.getBasicInfo().getUserGroup().code) {
- context.setValid(true);
- } else {
- context.setValid(false);
- }
- }
- }
-
- //规则3:判断当前用户是否在投放城市,具体逻辑省略
- public class CityInfoRule extends BasicRule<UserPortrait, UserPortraitRuleContext> {}
- //规则4:根据用户的活跃度进行资源过滤,具体逻辑省略
- public class UserPortraitRule extends BasicRule<UserPortrait, UserPortraitRuleContext> {}
-
- //我们通过spring将这些规则串起来组成一个一个请求链
- <bean name="serviceAvailableRule" class="com.dianping.takeaway.ServiceAvailableRule"/>
- <bean name="userGroupValidRule" class="com.dianping.takeaway.UserGroupRule"/>
- <bean name="cityInfoValidRule" class="com.dianping.takeaway.CityInfoRule"/>
- <bean name="userPortraitRule" class="com.dianping.takeaway.UserPortraitRule"/>
-
- <util:list id="userPortraitRuleChain" value-type="com.dianping.takeaway.Rule">
- <ref bean="serviceAvailableRule"/>
- <ref bean="userGroupValidRule"/>
- <ref bean="cityInfoValidRule"/>
- <ref bean="userPortraitRule"/>
- </util:list>
-
- //规则执行
- public class DefaultRuleEngine{
- @Autowired
- List<BasicRule> userPortraitRuleChain;
-
- public void invokeAll(RuleContext ruleContext) {
- for(Rule rule : userPortraitRuleChain) {
- rule.evaluate(ruleContext)
- }
- }
- }
责任链模式最重要的优点就是解耦,将客户端与处理者分开,客户端不需要了解是哪个处理者对事件进行处理,处理者也不需要知道处理的整个流程。在我们的系统中,后台的过滤规则会经常变动,规则和规则之间可能也会存在传递关系,通过责任链模式,我们将规则与规则分开,将规则与规则之间的传递关系通过Spring注入到List中,形成一个链的关系。当增加一个规则时,只需要实现BasicRule接口,然后将新增的规则按照顺序加入Spring中即可。当删除时,只需删除相关规则即可,不需要考虑代码的其他逻辑。从而显著地提高了代码的灵活性,提高了代码的开发效率,同时也保证了系统的稳定性。
今天的面试内容等主要参考了美团大大们的佳作,通过这段时间的面试童鞋们的沟通、反馈,发现不少问题都是重复的,但很多时候童鞋们并未能深入或者更有条例的讲解出来,导致于面试滑铁卢,所以接下来根据童鞋们的反馈、沟通等情况适当的往这个方面靠拢一下,大家有什么问题可以留言哦!

所属网站分类: 技术文章 > 博客
作者:以天使的名义
链接:http://www.javaheidong.com/blog/article/207314/dcd892d8104718948059/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力