

Java集合框架详解
发布于2021-05-29 23:16 阅读(1151) 评论(0) 点赞(12) 收藏(1)
Java集合框架详解
集合框架总览
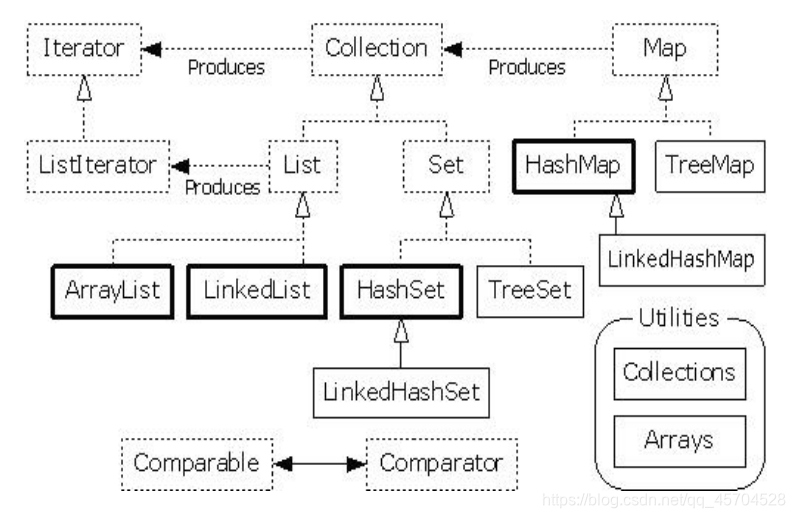
分为两大类:Collection和Map
Collection 接口存储一组不唯一,无序的对象
List 接口存储一组不唯一,有序(索引顺序)的对象
Set 接口存储一组唯一,无序的对象
Map 接口存储一组键值对象,提供 key 到 value 的映射,Key 唯一 无序,value 不唯一 无序
一.Collection集合
1.Collection集合的遍历(这里以ArrayList为例)
package org.example.data_structure.collection.list;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTest {
public static void main(String[] args) {
List<Integer> list=new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
//方法一,使用for循环(这种方法Set集合不适用)
for (int i = 0; i <list.size() ; i++) {
System.out.println(list.get(i));
}
//方法二:增强for循环
for(Integer elem:list){
System.out.println(elem);
}
//方法三:迭代器实现遍历(第一种和第二种的底层也是使用迭代器实现
Iterator<Integer> integerIterator=list.iterator();
while (integerIterator.hasNext()){
Integer elem=integerIterator.next();
System.out.println(elem);
}
//方法四:Lambda表达式+流式编程
list.forEach((elem)->System.out.println(elem));
//或者
list.forEach(System.out::println);
}
}
1.List
List 集合的主要实现类有 ArrayList 和 LinkedList,分别是数据结构中顺序表和链表的 实现。另外还包括栈和队列的实现类:Deque 和 Queue。
特点:有序,不唯一
<1>.ArrayList
在内存中分配连续的空间,实现了长度可变的数组
• 优点:遍历元素和随机访问元素的效率比较高
• 缺点:添加和删除需大量移动元素效率低,按照内容查询效率低
ArrayList的部分源码分析:
ArrayList 底层就是一个长度可以动态增长的 Object 数组
public class ArrayList<E> extends AbstractList<E> implements
List<E>, RandomAccess, Cloneable, Serializable {
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[]
DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
}
JDK1.7中,使用无参数构造方法创建ArrayList对象时,默认底层数组长度是10。
JDK1.8中,使用无参数构造方法创建ArrayList对象时,默认底层数组长度是0;
jdk1.8中,当第一次添加元素时候,如果容量不足则需要扩容
•容量不足时进行扩容,默认扩容50%。如果扩容50%还不足容纳新增元素,就扩容为能容纳新增元素的最小数量。
源码如下:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
使用移位操作,将容量扩充百分之50,如果还不够,则扩充为最小需要的容量,然后使用Arrays.copyof扩充
<2>LinkedList
采用双向链表存储方式。
缺点:遍历和随机访问元素效率低下
优点:插入、删除元素效率比较高

LinkedList的源码分析:
LinkedList的底层是一个双向链表,其中有两个成员变量分别指向链表的头结点和尾结点
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
transient int size = 0;//节点的数量
transient Node<E> first; //指向第一个节点
transient Node<E> last; //指向最后一个节点
public LinkedList() { }
}
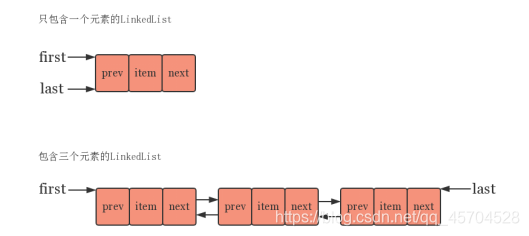
含有一个静态内部类,表示链表的结点
private static class Node<E> {
E item;//存储节点的数据
Node<E> next;//指向后一个节点
Node<E> prev; //指向前一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList也实现了Queue接口,Deque接口,可以用作队列和栈使用
2.Set
特点:无序,唯一(不重复)
<1>HashSet
采用Hashtable哈希表存储结构
优点:添加速度快 查询速度快 删除速度快
缺点:无序
<2>LinkedHashSet
也是使用Hash表存储结构,加上链表来维护元素添加顺序
<3>TreeSet
采用二叉树(红黑树)的存储结构
优点:有序 查询速度比List快(按照内容查询)
缺点:查询速度没有HashSet快
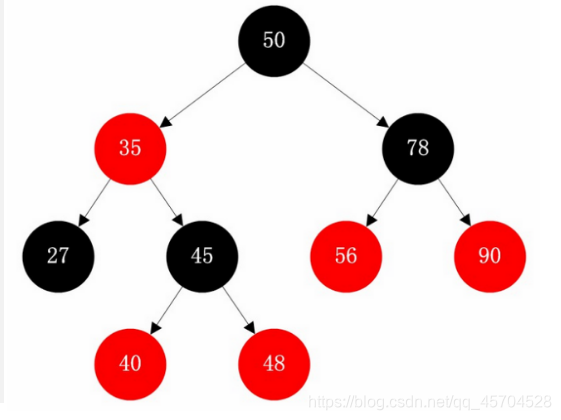
Set的源码分析在下面会和Map的源码分析放在一起
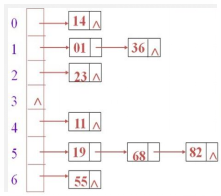
四.Hash表
简单来说
Hash表可以按照内容查找,不进行比较,而是通过计算得到地址,实现类似数组按照索引查询的高效率O(1)
Hash表的结构:主结构:顺序表,每个顺序表的节点在单独引出一个链表
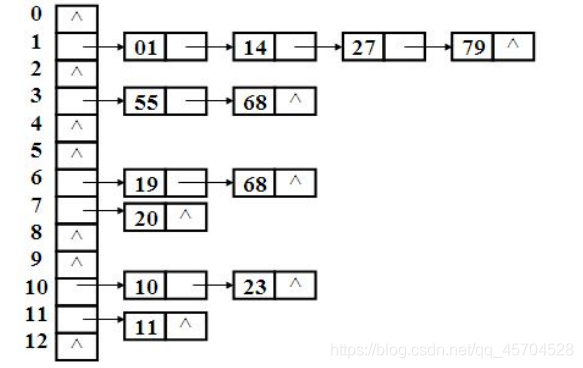
Hash是如何添加数据的?
1)计算哈希 码(调用hashCode(),结果是一个int值,整数的哈希码取自身即可)
2)计算在哈希表中的存储位置 y=k(x)=x%11(哈希函数)
x:哈希码 k(x) 函数y:在哈希表中的存储位置
3)存入哈希表
情况1:一次添加成功
情况2:多次添加成功(出现了冲突,调用equals()和对应链表的元素进行比较,比较到最后,结果都是false,创建新节点,存储数据,并加入链表末尾)
情况3:不添加(出现了冲突,调用equals()和对应链表的元素进行比较, 经过一次或者多次比较后,结果是true,表明重复,不添加)
结论1:哈希表添加数据快(3步即可,不考虑冲突)
结论2:唯一、无序
hashCode和equals到底有什么神奇的作用?
hashCode():计算哈希码,是一个整数,根据哈希码可以计算出数据在哈希表中的存储位置
equals():添加时出现了冲突,需要通过equals进行比较,判断是否相同;查询时也需要使用equals进行比较,判断是否相同
hashCode的获取: 尽量让不同的对象的Hash值不同
装填因子: 装填因子=表中的记录数/哈希表的长度 装填因子越大,发生冲突几率越大,0.5为最佳
三.Map
• Map• 特点:存储的键值对映射关系,根据 key 可以找到 value
Map的遍历
//map的遍历
//1. 获取所有的key
Set<String> set=map.keySet();
for(String key : set){
System.out.println(key+":"+map.get(key));
}
//2.使用entrySet
Set<Map.Entry<String,String>> entrySet=map.entrySet();
Iterator<Map.Entry<String,String>> iterator=entrySet.iterator();
while (iterator.hasNext()){
Map.Entry<String,String> it=iterator.next();
System.out.println(it.getKey()+":"+it.getValue());
}
结构图和上述Set类似
• HashMap
• 采用 Hashtable 哈希表存储结构(神奇的结构)
• 优点:添加速度快 查询速度快 删除速度快
• 缺点:key 无序
• LinkedHashMap
• 采用哈希表存储结构,同时使用链表维护次序
• key 有序(添加顺序)
• TreeMap
• 采用二叉树(红黑树)的存储结构
• 优点:key 有序 查询速度比 List 快(按照内容查询)
• 缺点:查询速度没有 HashMap 快
四.内部比较器和外部比较器
1.内部比较器(实现了Comparable接口)
外部比较器可以让类实现Comparable接口,重写compareTo方法但是他的判断条件有限,只能有一个
例如:以下学生类按照name进行排序(升序)
public class Student implements Comparable<Student>{
private String name;
private String sex;
private int age;
private double score;
@Override
public int compareTo(Student other) {
return this.name.compareTo(other.name);
//return this.age - other.age;
}
}
2.外部比较器(实现了Comparator接口)
需要一个新的类,实现Comparator接口,重写compare方法,可以指定多个排序条件
还是以上述Student类为例,建立一个新的类
import java.util.Comparator;
public class StuScoreNameDescComparator implements Comparator<Student> {
@Override
public int compare(Student stu1, Student stu2) {
if(stu1.getScore()>stu2.getScore()){
return 1;
}else if(stu1.getScore()<stu2.getScore()){
return -1;
}else{
// return 0;
return -stu1.getName().compareTo(stu2.getName());
}
//return (int)(stu1.getScore()-stu2.getScore()); // 98.5 -98 =0.5 --->0
}
}
五.Map和Set的源码分析
Set的底层是使用Map实现的
1.HashMap和HashSet
<1>HashMap
HashMap的源码:
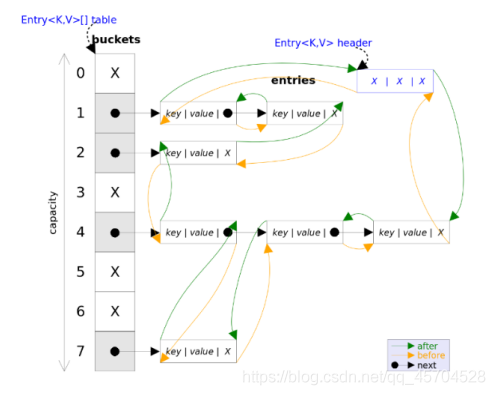
JDK1.7 及其之前,HashMap 底层是一个 table 数组+链表实现的哈希表存储结构,而jdk1.8采用table数组+链表/红黑树
如图1.7的存储结构:
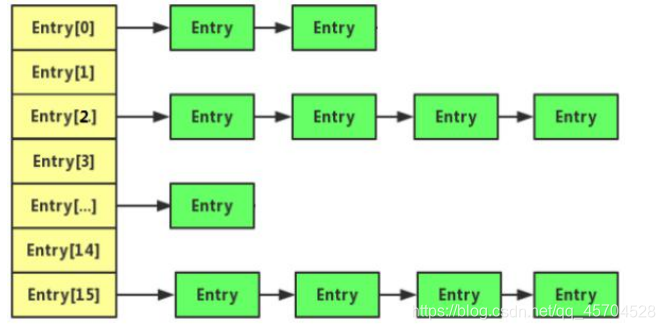
jdk1.8的存储结构:
当链表的存储数据个数大于等于 8 的时候,不再采用链 表存储,而采用红黑树存储结构。这么做主要是查询的时间复杂度上,链表为 O(n), 而红黑树一直是 O(logn)。如果冲突多,并且超过 8,采用红黑树来提高效率,而当结点减少,小于等于6时,会重新变回链表结构
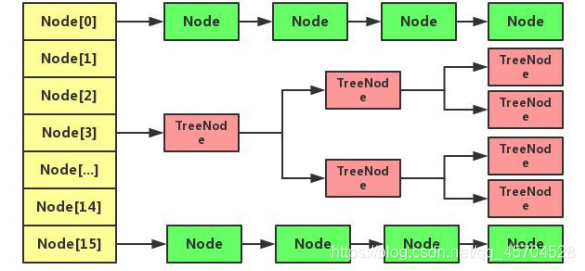
链表中每一个结点Entry,结构如下:
static class Entry<K, V> implements Map.Entry<K, V> {
final K key; //key
V value;//value
Entry<K, V> next; //指向下一个节点的指针
int hash;//哈希码
}
HsahMap主要成员:
public class HashMap<K, V> implements Map<K, V> {
//哈希表主数组的默认长度
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认的装填因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//主数组的引用
transient Entry<K, V>[] table;
int threshold;//界限值 阈值
final float loadFactor;//装填因子
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor;//0.75
threshold = (int) Math.min(capacity * loadFactor,
MAXIMUM_CAPACITY + 1);//16*0.75=12
table = new Entry[capacity];
}
}
调用put方法添加键值对。哈希表三步添加数据原理的具体实现;是计算key的哈希码,和value无关
1.第一步计算哈希码时,不仅调用了key的hashCode(),还进行了更复杂处理,目的是尽量保证不同的key尽量得到不同的哈希码
2.第二步根据哈希码计算存储位置时,使用了位运算提高效率。同时也要求主数组长度必须是2的幂)
3.第三步添加Entry时添加到链表末尾(jdk1.8),jdk1.7是添加到头部
4.如果索引处为空,则直接插入到对应的数组中,否则,判断是否是红黑树,若是,则红黑树插入,否则遍历链表,若长度不小于8,则将链表转为红黑树,转成功之后 再插入。如果插入的key为null,则直接插入到hash表数组索引为0的位置
5.第三步添加Entry是发现了相同的key已经存在,就使用新的value替代旧的value,并且返回旧的value
put部分源码:
public class HashMap {
public V put(K key, V value) {
//如果key是null,特殊处理
if (key == null) return putForNullKey(value);
//1.计算key的哈希码hash
int hash = hash(key);
//2.将哈希码代入函数,计算出存储位置 y= x%16;
int i = indexFor(hash, table.length);
//如果已经存在链表,判断是否存在该key,需要用到equals()
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如找到了,使用新value覆盖旧的value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;// the United States
e.value = value;//America
e.recordAccess(this);
return oldValue;
}
}
//添加一个结点
addEntry(hash, key, value, i);
return null;
}
final int hash(Object k) {
int h = 0;
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
//作用就相当于y = x%16,采用了位运算,效率更高
return h & (length-1);
}
}
添加元素时如达到了阈值(默认为16*0.75=12),需扩容,每次扩容为原来主数组容量的2倍:
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果达到了门槛值,就扩容,容量为原来容量的2位 16---32
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//添加节点
createEntry(hash, key, value, bucketIndex);
}
<2>HashSet
•HashSet的底层使用的是HashMap,所以底层结构也是哈希表
•HashSet的元素到HashMap中做key,value统一是同一个Object() —>这个Object用处不大,指向同一个Object而不是每次添加都new,节省空间
HashSet的部分源码:
public class HashSet<E> implements Set<E> {
private transient HashMap<E, Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, new Object()) == null;
return map.put(e, PRESENT) == null;
}
public int size() {
return map.size();
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
}
2.TreeMap和TreeSet
<1>TreeMap
TreeMap源码分析:
基本特征:二叉树、二叉查找树、二叉平衡树、红黑树
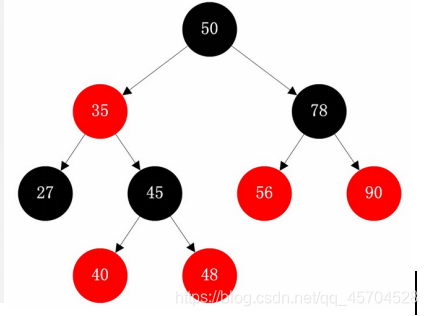
每个结点的结构:

static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
TreeMap主要的成员变量
public class TreeMap<K, V> implements NavigableMap<K, V> {
private final Comparator<? super K> comparator;//外部比较器
private transient Entry<K, V> root = null; //红黑树根节点的引用
private transient int size = 0;//红黑树中节点的个数
public TreeMap() {
comparator = null;//没有指定外部比较器
}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;//指定外部比较器
}
}
TreeMap的put原理
•从根节点开始比较
•添加过程就是构造二叉平衡树的过程,会自动平衡
•平衡离不开比较:外部比较器优先,然后是内部比较器。如果两个比较器都没有,就抛出异常(因此key无法为null)
添加的部分源码:
public V put(K key, V value) {
Entry<K,V> t = root;
//如果是添加第一个节点,就这么处理
if (t == null) {
//即使是添加第一个节点,也要使用比较器
compare(key, key); // type (and possibly null) check
//创建根节点 //此时只有一个节点
size = 1;
return null;
}
//如果是添加非第一个节点,就这么处理
int cmp;
Entry<K,V> parent;
Comparator<? super K> cpr = comparator;
//如果外部比较器存在,就使用外部比较器
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;//在左子树中查找
else if (cmp > 0)
t = t.right; //在右子树查找
else
//找到了对应的key,使用新的value覆盖旧的value
return t.setValue(value);
} while (t != null);
}
else {
//如果外部比较器没有,就使用内部比较器
....
}
//找到了要添加的位置,创建一个新的节点,加入到树中
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
size++;
return null;
}
root = new Entry<>(key, value, null);
<2>TreeSet
TreeSet的底层使用的是TreeMap,所以底层结构也是红黑树
TreeSet的元素e是作为TreeMap的key存在的,value统一为同一个 Object()
部分源码:
public class TreeSet<E> implements NavigableSet<E> {
//底层的TreeMap的引用
private transient NavigableMap<E, Object> m;
private static final Object PRESENT = new Object();
public TreeSet() {
//创建TreeSet对象就是创建一个TreeMap对象
this(new TreeMap<E, Object>());
}
TreeSet(NavigableMap<E, Object> m) {
this.m = m;
}
public boolean add(E e) {
return m.put(e, PRESENT) == null;
}
public int size() {
return m.size();
}
}
六.集合的其他内容
1.迭代器
<1>Iterator迭代器
Iterator专门为遍历集合而生,集合并没有提供专门的遍历的方法
Iterator实际上迭代器设计模式的实现
Iterator的常用方法
boolean hasNext(): 判断是否存在另一个可访问的元素
Object next(): 返回要访问的下一个元素
void remove(): 删除上次访问返回的对象。
哪些集合可以使用Iterator遍历
层次1:Collection、List、Set可以、Map不可以
层次2:提供iterator()方法的就可以将元素交给Iterator;
层次3:实现Iterable接口的集合类都可以使用迭代器遍历(最核心)
for-each循环和Iterator的联系
for-each循环(遍历集合)时,底层使用的是Iterator
凡是可以使用for-each循环(遍历的集合),肯定也可以使用Iterator进行遍历
for-each循环和Iterator的区别
for-each还能遍历数组,Iterator只能遍历集合
使用for-each遍历集合时不能删除元素,会抛出异常ConcurrentModificationException使用Iterator遍历合时能删除元素
Iterator是一个接口,它的实现类在哪里?
在相应的集合实现类中 ,比如在ArrayList中存在一个内部了Itr implements Iterator
为什么Iterator不设计成一个类,而是一个接口
不同的集合类,底层结构不同,迭代的方式不同,所以提供一个接口,让相应的实现类来实现
示例:
public static void main(String[] args) {
List<Integer> list=new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
Iterator<Integer> integerIterator=list.iterator();
while (integerIterator.hasNext()){
Integer elem=integerIterator.next();
System.out.println(elem);
}
}
<2>.ListIterator
ListIterator和Iterator的关系
public interface ListIterator extends Iterator
都可以遍历List
ListIterator和Iterator的区别
使用范围不同
Iterator可以应用于更多的集合,Set、List和这些集合的子类型。
ListIterator只能用于List及其子类型。
遍历顺序不同
Iterator只能顺序向后遍历; ListIterator还可以逆序向前遍历
Iterator可以在遍历的过程中remove();ListIterator可以在遍历的过程中remove()、add()、set()
ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
示例:
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList();
//添加元素
list.add(80);
list.add(90);
list.add(80);
list.add(70);
ListIterator<Integer> lit = list.listIterator();
//从前向后遍历
while(lit.hasNext()){
int elem = lit.next();
System.out.println(elem+" "+lit.previousIndex()+" "+lit.nextIndex());
}
System.out.println("================");
//从后向前遍历
while(lit.hasPrevious()){
int elem = lit.previous();
System.out.println(elem+" "+lit.previousIndex()+" "+lit.nextIndex());
}
}
2.Collections集合类
这个集合类无法创建,唯一的构造方式是私有的,里面的方法直接通过类名调用
public static void main(String[] args) {
//给集合快速赋值
List<Integer> list = new ArrayList<>();
Collections.addAll(list,50,40,70,60,80,34,100,76);
System.out.println(list);
//排序
Collections.sort(list);
System.out.println(list);
//查找元素(元素必须有序)
int index = Collections.binarySearch(list,80);
System.out.println(index);
//最大值最小值
System.out.println(Collections.max(list));
System.out.println(Collections.min(list));
//填充集合
//Collections.fill(list,100);
System.out.println(list);
//复制集合
List<Integer> list2 = new ArrayList<>();
Collections.addAll(list2,0,0,0,0,0,0,0,0,0,0,0,0);
Collections.copy(list2,list);//目的dest集合的size>=源集合src的size
System.out.println(list);
System.out.println(list2);
//同步集合!!!
StringBuffer buffer;//线程同步 synchronized 上锁
StringBuilder builder;//线程不同步
ArrayList list3;//线程不安全 没有上锁 多线程操作会有安全问题
//进去是一个不安全的集合
//返回的是一个安全的集合
List list4 = Collections.synchronizedList(list);
//List <Integer> list4 = new Collections.SynchronizedRandomAccessList<>(list);
list4.add(90);
Set<Integer> set=new HashSet<>();
Set<Integer> set1=Collections.synchronizedSet(set);
}
3.旧的集合类(Vector和Hashtbale)
Vector
实现原理和ArrayList相同,功能相同,都是长度可变的数组结构,很多情况下可以互用
两者的主要区别如下
Vector是早期JDK接口,ArrayList是替代Vector的新接口
Vector线程安全,效率低下;ArrayList重速度轻安全,线程非安全
长度需增长时,Vector默认增长一倍,ArrayList增长50%
Hashtable类
实现原理和HashMap相同,功能相同,底层都是哈希表结构,查询速度快,很多情况下可互用
两者的主要区别如下
Hashtable是早期JDK提供,HashMap是新版JDK提供
Hashtable继承Dictionary类,HashMap实现Map接口
Hashtable线程安全,HashMap线程非安全
Hashtable不允许null值,HashMap允许null值
4.新一代的并发集合类(JUC包)
<1>ConcurrentHashMap
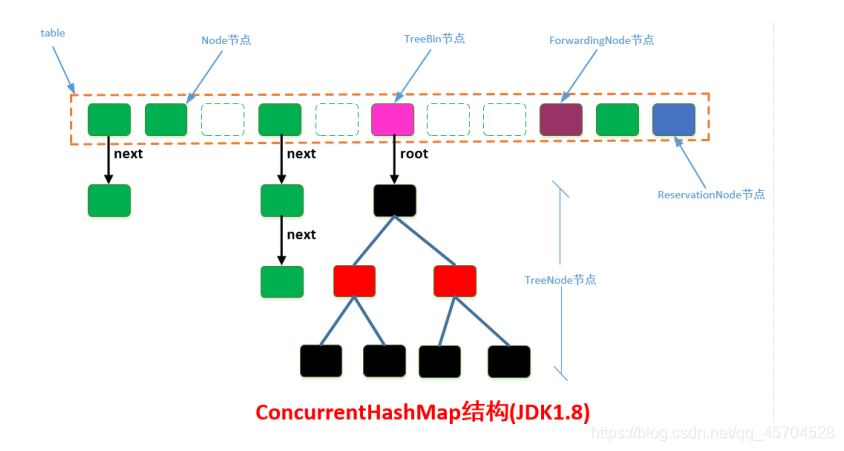
结点结构:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
1.底层的数据结构和HashMap jdk1.8版本一样,都是基于数组+链表+红黑树
2.支持多线程的并发操作,实现原理:CAS+Synchronized保证并发更新
3.put方法存储元素时,通过key的hashCode计算出相应数组的索引,如果没有Node,CAS自旋直到插入成功;如果存在Node,则使用synchronized 锁住改Node元素(链表或者红黑树)
4.键,值迭代器为弱一致性迭代器,创建迭代器之后,可以对元素进行更新
5.读操作没有加锁,value是volatile修饰的,保证了可见性,所以是安全的
6.读写分离可以提高效率:多线程多不同的Node/Segment的插入/删除操作是可以并发,并行的,多同一个Node/Segment的作用是互斥的。读操作都是无锁操作,可以并发,并行执行
<2>CopyOnWriteArrayList
CopyOnWriteArrayList :CopyOnWrite+Lock锁
对于set()、add()、remove()等方法使用ReentrantLock的lock和unlock来加锁和解锁。读操作不需要加锁(之前集合安全类,即使读操作也要加锁,保证数据的实时一致)。
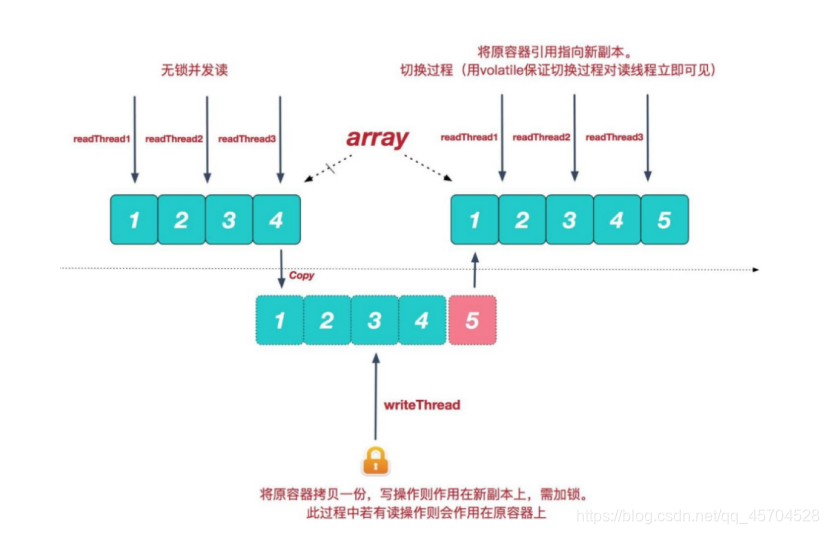
当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,
添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite容器只能保证数据的最终一致性,不能保证数据实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
部分源码:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 复制出新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 把新元素添加到新数组里
newElements[len] = e;
// 把原数组引用指向新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
public E get(int index) {
return get(getArray(), index);
}
<3>CopyOnWriteArraySet
CopyOnWriteArraySet:CopyOnWrite+Lock锁
它是线程安全的无序的集合,可以将它理解成线程安全的HashSet
底层是由CopyOnWriteArrayList 实现,思想大致相同
原文链接:https://blog.csdn.net/qq_45704528/article/details/117320155
所属网站分类: 技术文章 > 博客
作者:我是不是很美
链接:http://www.javaheidong.com/blog/article/207771/bf1e7e294c78ee672a7d/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力