

基于flink实现的worldcount
发布于2021-06-12 14:02 阅读(386) 评论(0) 点赞(27) 收藏(0)
Flink框架主要应用针对流式数据进行有状态计算。
Flink使用java语言开发,提供了scala编程的接口。使用java或者scala开发Flink是需要使用jdk8版本,如果使用Maven,maven版本需要使用3.0.4及以上,Flink同时也支持使用python进行开发,需要在python中安装PyFlink 包
本实例基于flink1.7.1。
创建maven工程,pom配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wh.flink</groupId>
<artifactId>flink</artifactId>
<version>1.0-SNAPSHOT</version>
<name>flink</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.7.1</flink.version>
</properties>
<dependencies>
<!-- Flink 依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<!-- Flink Kafka连接器的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- Flink 开发Scala需要导入以下依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<!--<dependency>-->
<!--<groupId>org.scala-lang</groupId>-->
<!--<artifactId>scala-library</artifactId>-->
<!--<version>2.11.12</version>-->
<!--</dependency>-->
<!-- log4j 和slf4j 包,如果在控制台不想看到日志,可以将下面的包注释掉-->
<!--<dependency>-->
<!--<groupId>org.slf4j</groupId>-->
<!--<artifactId>slf4j-log4j12</artifactId>-->
<!--<version>1.7.25</version>-->
<!--<scope>test</scope>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>log4j</groupId>-->
<!--<artifactId>log4j</artifactId>-->
<!--<version>1.2.17</version>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>org.slf4j</groupId>-->
<!--<artifactId>slf4j-api</artifactId>-->
<!--<version>1.7.25</version>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>org.slf4j</groupId>-->
<!--<artifactId>slf4j-nop</artifactId>-->
<!--<version>1.7.25</version>-->
<!--<scope>test</scope>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>org.slf4j</groupId>-->
<!--<artifactId>slf4j-simple</artifactId>-->
<!--<version>1.7.5</version>-->
<!--</dependency>-->
</dependencies>
<build>
<plugins>
<!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.lw.java.myflink.Streaming.example.FlinkReadSocketData</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
创建需要统计数据的words文件
hello java
hello hadoop
hello scala
hello storm
hello spark
hello flink
hello java
hello hadoop
hello scala
hello storm
hello spark
hello flink
创建FlinkWorldCount 类,代码如下
public class FlinkWorldCount {
public static void main(String[] args) throws Exception {
//创建环境
StreamExecutionEnvironment env1=StreamExecutionEnvironment.getExecutionEnvironment();
LocalStreamEnvironment env2=StreamExecutionEnvironment.createLocalEnvironment();
ExecutionEnvironment env=ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文件
DataSource<String>dataSource=env.readTextFile("./data/words");
FlatMapOperator<String,String>words=dataSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String []split=line.split(" ");
for (String word : split) {
out.collect(word);
}
}
});
MapOperator<String,Tuple2<String,Integer>>map=words.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2 <String,Integer>map(String word) throws Exception {
return new Tuple2<>(word,1);
}
});
UnsortedGrouping<Tuple2<String,Integer>>grouping=map.groupBy(0);
DataSet<Tuple2<String,Integer>>sum=grouping.sum(1);
SortPartitionOperator<Tuple2<String,Integer>>result=sum.sortPartition(1, Order.DESCENDING);
//打印运行结果
sum.print();
// 将运行结果写入到文件中
// DataSink<Tuple2<String,Integer>>tuple2DataSink=result.writeAsCsv("./data/reuslt",";","=", FileSystem.WriteMode.OVERWRITE);
// env.execute();
}
}
执行结果如下
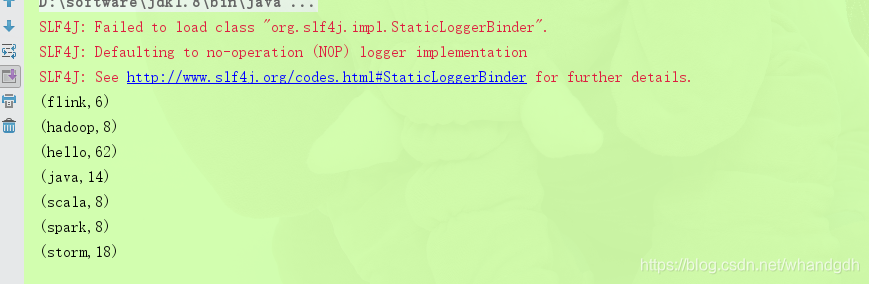
将执行结果写入到文件中,
最后代码调整如下:
//sum.print(); 【print、count、collect自带触发功能,不需要env.execute()】
// 将运行结果写入到文件中
DataSink<Tuple2<String,Integer>>tuple2DataSink=result.writeAsCsv("./data/reuslt",";","=", FileSystem.WriteMode.OVERWRITE);
env.execute();
执行结果
看到在data目录下创建了result文件,并将结果写入到了result文件中。

原文链接:https://blog.csdn.net/whandgdh/article/details/117719543
所属网站分类: 技术文章 > 博客
作者:快起来搬砖啦
链接:http://www.javaheidong.com/blog/article/222337/3bdbf8dbf84ea25f1886/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力