

开源 SPL 助力 JAVA 处理公共数据文件(txt\csv\json\xml\xls)
发布于2022-08-07 19:54 阅读(1456) 评论(0) 点赞(13) 收藏(1)
在 JAVA 应用中经常要处理 txt\csv\json\xml\xls 这类公共格式的数据文件,直接用 JAVA 硬写会非常麻烦,通常要借助一些现成的开源包,但这些开源包也都有各自的不足。
解析库。这种类库解决了从外部文件到内部对象的问题,比硬编码取数好写,常见的有解析 txt\csv 的 OpenCSV,解析 json 的 SJ.json\Gson\JsonPath,解析 xml 的XOM\Xerces-J\Jdom\Dom4J,解析 xls 的 POI。其中,JsonPath 支持 JsonPath 语法,Dom4J 等支持 XPath 语法,可以进行简单的过滤运算。但总的来说,这种类库的计算能力很弱,要借助硬编码或其他类库完成计算。
Spark。Spark 是 Scala 语言的计算类库,支持结构化数据文件,计算能力较强。Spark 的缺点在于缺乏解析能力,需要第三方类库的支持,不如原生类库方便稳定,比如 spark-xml 用于解析 xml,spark-excel 或 poi 用于解析 xls。Scala 语言本身也存在缺点,学习曲线远比 Java 陡峭,学习成本过高;版本稳定性差,不利于工程应用。
内嵌数据库。把文件解析后写入内嵌数据库,就可以利用 SQL 强大的计算能力,常见的有 SQLite\HSQLDB\Derby。但入库过程很繁琐,延迟很致命,整体架构也很复杂。计算能力强大也是相对的,SQL 只擅长计算二维结构的数据,不擅长计算 json\xml 这类多层结构的数据。
还有一些类库也可以计算结构化数据文件,比如 simoc csvjdbc\xiao321 csvjdb\xlsjdbc 等文件 JDBC,Tablesaw\Joinery 等 DataFrame,但因为成熟度低计算能力弱,实用价值就更小了。
相比以上类库,esProc SPL 是更好的选择。
SPL 是基于 JVM 的开源程序语言,提供了简易的解析方法以读取各类规则或不规则的 txt\csv\json\xml\xls;专业的数据对象能统一地表达二维结构数据和多层结构数据;丰富的计算函数可满足业务中的计算需求。
txt\csv
SPL 内置多种解析函数,可以用简单代码解析各类文本,并提供了丰富的计算函数,可以统一计算解析后的文本。
格式规则的文本。二维结构的文本类似数据库表,首行是列名,其他行每行一条记录,列之间用固定符号分隔。其中,以逗号为分隔符的 csv 和以 tab 为分隔符的 txt 格式最为常见。SPL 的 T 函数用一行代码就可以解析:
s=T("D:\\data\\Orders.csv")
格式不规则的文本,可以使用选项丰富的 import 函数。比如分隔符为双横线的文本:
s=file("D:/Orders.txt").import@t(;,"--")
丰富的计算函数。对于解析后的文本,SPL 可以轻松完成 SQL 式计算。
过滤:
s.select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
排序:
s.sort(Client,-Amount)
去重:
s.id(Client)
分组汇总:
s.groups(year(OrderDate);sum(Amount))
关联:
join(T ("D:/data/Orders.csv"):O,SellerId; T("D:/data/Employees.txt"):E,EId)
TopN:
s.top(-3;Amount)
组内 TopN:
s.groups(Client;top(3,Amount))
更不规则的文本,通常无法直接解析成结构化数据,SPL 提供了灵活的函数语法,只要简单处理就能够获得理想数据。比如文件每三行对应一条记录,其中第二行含多个字段,将该文件整理成结构化数据,并按第 3 和第 4 个字段排序:
| A | |
|---|---|
| 1 | =file(“D:\data.txt”).import@si() |
| 2 | =A1.group((#-1)\3) |
| 3 | =A2.new(~(1):OrderID, (line=(2).array(“\t”))(1):Client,line(2):SellerId,line(3):Amount,(3):OrderDate ) |
| 4 | =A3.sort(_3,_4) |
SPL 还提供了符合SQL92 标准的语法,包括集合计算、case when、with、嵌套子查询等。比如分组汇总可以写作:
$select year(OrderDate),sum(Amount) from D:/data/Orders.txt group by year(OrderDate)
json\xml
SPL 不仅支持二维结构的文本,还可以方便地处理 json\xml 这样的多层结构数据,自由访问不同层级,并用统一的代码进行计算。
专业的多层结构数据对象。SPL 可以方便地表达 json\xml 的层级结构。比如,从文件读取多层 json 串并解析:
| A | |
|---|---|
| 1 | =file(“d:\xml\emp_orders.json”).read() |
| 2 | =json(A1) |
可以看到多层结构:
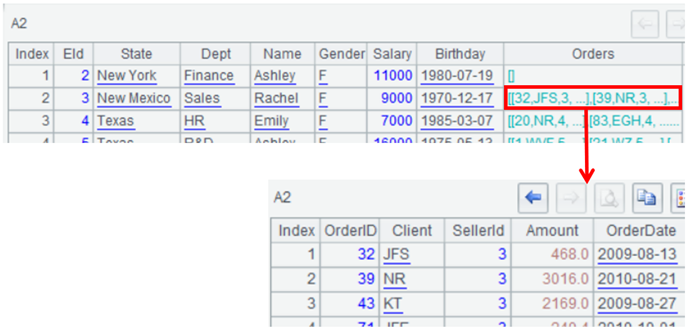
xml也是类似:
| A | |
|---|---|
| 1 | =file(“d:\xml\emp_orders.xml”).read() |
| 2 | =xml(A1,“xml/row”) |
| 访问多层结构数据。可以通过点号访问不同的层级,通过下标访问不同的位置。 |
Client 字段构成的集合:
A2.(Client)
第 10 条记录的 Orders 字段(所含的二维表):
A2(10).Orders
第 10 条件记录的 Orders 字段下的第 5 条记录:
(A2(10).Orders)(5)
计算多层数据。SPL 可以用统一的代码计算二维结构数据和多层结构数据:
| A | |
|---|---|
| 3 | =A2.conj(Orders).groups(year(OrderDate);sum(Amount)) |
| 4 | =A2(10).Orders.select(Amount>1000 && Amount<=3000 && like(Client,“s”)) |
网络多层结构数据。除了 json\xml 这样的本地文件,SPL 也支持 WebSerivce 和 Restful 这类网络服务上的多层结构数据。比如,从 Restful 取多层 json,进行条件查询:
| A | |
|---|---|
| 1 | =httpfile(“http://127.0.0.1:6868/restful/emp_orders”).read() |
| 2 | =json(A1) |
| 3 | =A2.conj(Orders) |
| 4 | =A3.select(Amount>1000 && Amount<=2000 && like@c(Client,“business”)) |
| 很多特殊数据源也是多层结构数据,常见的比如 MongoDB、ElasticSearch、SalesForce,SPL 可直接从这些数据源取数并计算。 |
xls
SPL 对 POI 进行了高度封装,可以轻松读写格式规则或不规则的 xls,并用 SPL 函数和语法统一进行计算。
格式规则的行式 xls,仍然用 T 函数读取:
=T("d:\\Orders.xls")
后继的计算也和文本类似。
生成格式规则的行式 xls,可以用 xlsexport 函数。比如,将 A1 写入新 xls 的第一个 sheet,首行为列名,只要一句代码:
=file("e:/result.xlsx").xlsexport@t(A1)
xlsexport 函数的功能丰富多样,可以将序表写入指定 sheet,或只写入序表的部分行,或只写入指定的列:
=file("e:/scores.xlsx").xlsexport@t(A1,No,Name,Class,Maths)
xlsexport 函数还可以方便地追加数据,比如对于已经存在且有数据的 xls,将序表 A1 追加到该文件末尾,外观风格与原文件末行保持一致:
=file("e:/scores.xlsx").xlsexport@a(A1)
格式较不规则的行式 xls,可使用 xlsimport 函数读取,功能丰富而简洁。
没有列名,首行直接是数据:
file("D:\\Orders.xlsx").xlsimport()
跳过前 2 行的标题区:
file("D:/Orders.xlsx").xlsimport@t(;,3)
从第 3 行读到第 10 行:
file("D:/Orders.xlsx").xlsimport@t(;,3:10)
只读取其中 3 个列:
file("D:/Orders.xlsx").xlsimport@t(OrderID,Amount,OrderDate)
读取名为 “sales” 的特定 sheet:
file("D:/Orders.xlsx").xlsimport@t(;"sales")
函数 xlsimport 还具有读取倒数 N 行、密码打开文件、读大文件等功能,这里不再详述。
格式自由的 xls。SPL 提供了 xlscell 函数,可以读写指定 sheet 里指定片区的数据,比如读取第 1 个 sheet 里的 A2 格:
=file("d:/Orders.xlsx").xlsopen().xlscell("C2")
配合 SPL 灵活的语法,就可以解析自由格式的 xls,比如将下面的文件读为规范的二维表(序表):
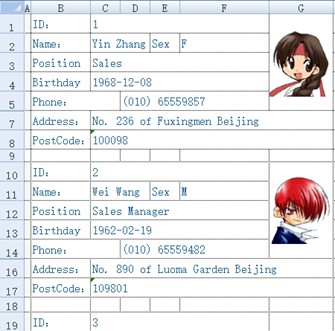
这个文件格式很不规则,直接基于 POI 写 JAVA 代码是个浩大的工程,而 SPL 代码就简短得多:
| A | B | C | |
| 1 | =create(ID,Name,Sex,Position,Birthday,Phone,Address,PostCode) | ||
| 2 | =file("e:/excel/employe.xlsx").xlsopen() | ||
| 3 | [C,C,F,C,C,D,C,C] | [1,2,2,3,4,5,7,8] | |
| 4 | for | =A3.(~/B3(#)).(A2.xlscell(~)) | |
| 5 | if len(B4(1))==0 | break | |
| 6 | >A1.record(B4) | ||
| 7 | >B3=B3.(~+9) | ||
不规则片区写入数据,同样使用 xlscell 函数。比如,xls 中蓝色单元格是不规则的表头,需要在相应的白色单元格中填入数据,如下图:
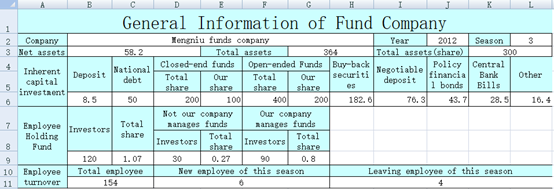
直接用 POI 要大段冗长的代码,而 SPL 代码就简短许多:
| A | B | C | D | E | F | |
| 1 | Mengniu Funds | 2017 | 3 | 58.2 | 364 | 300 |
| 2 | 8.5 | 50 | 200 | 100 | 400 | 200 |
| 3 | 182.6 | 76.3 | 43.7 | 28.5 | 16.4 | |
| 4 | 120 | 1.07 | 30 | 0.27 | 90 | 0.8 |
| 5 | 154 | 6 | 4 | |||
| 6 | =file("e:/result.xlsx") | =A6.xlsopen() | ||||
| 7 | =C6.xlscell("B2",1;A1) | =C6.xlscell("J2",1;B1) | =C6.xlscell("L2",1;C1) | |||
| 8 | =C6.xlscell("B3",1;D1) | =C6.xlscell("G3",1;E1) | =C6.xlscell("K3",1;F1) | |||
| 9 | =C6.xlscell("B6",1;[A2:F2].concat("\t")) | =C6.xlscell("H6",1;[A3:E3].concat("\t")) | ||||
| 10 | =C6.xlscell("B9",1;[A4:F4].concat("\t")) | =C6.xlscell("B11",1;[A5:C5].concat("\t")) | ||||
| 11 | =A6.xlswrite(B6) | |||||
上面第 6、9、11 行有连续单元格,SPL 可以简化代码一起填入,POI 只能依次填入。
更强的计算能力
SPL 有更丰富的日期和字符串函数、更方便的语法,能有效简化 SQL 和存储过程难以实现的复杂计算。
更丰富的日期和字符串函数。除了常见的日期增减、截取字符串等函数,SPL 还提供了更丰富的日期和字符串函数,在数量和功能上远远超过了 SQL:
季度增减:
elapse@q("2020-02-27",-3) //返回2019-05-27
N 个工作日之后的日期:
workday(date("2022-01-01"),25) //返回2022-02-04
字符串类函数,判断是否全为数字:
isdigit("12345") //返回true
取子串前面的字符串:
substr@l("abCDcdef","cd") //返回abCD
按竖线拆成字符串数组:
"aa|bb|cc".split("|") //返回["aa","bb","cc"]
SPL 还支持年份增减、求季度、按正则表达式拆分字符串、拆出 SQL 的 where 或 select 部分、拆出单词、按标记拆 HTML 等大量函数。
更方便的语法。SPL 提供了函数选项,使功能相似的函数可以共用一个函数名,只用函数选项区分差别。比如 select 函数的基本功能是过滤,如果只过滤出符合条件的第 1 条记录,可使用选项 @1:
T.select@1(Amount>1000)
二分法排序,即对有序数据用二分法进行快速过滤,使用 @b:
T.select@b(Amount>1000)
有序分组,即对分组字段有序的数据,将相邻且字段值相同的记录分为一组,使用 @b:
T.groups@b(Client;sum(Amount))
函数选项还可以组合搭配,比如:
Orders.select@1b(Amount>=1000)
结构化运算函数的参数有些很复杂,比如 SQL 就需要用各种关键字把一条语句的参数分隔成多个组,但这会动用很多关键字,也使语句结构不统一。SPL 使用层次参数简化了复杂参数的表达,即通过分号、逗号、冒号自高而低将参数分为三层:
join(Orders:o,SellerId ; Employees:e,EId)
逻辑复杂的计算。SPL 计算能力强,对于 SQL 和存储过程难以实现的有序运算、集合运算、关联计算、分步计算,SPL 通常可以轻松实现。比如,计算某支股票最长的连续上涨天数:
| A | |
|---|---|
| 1 | // 解析文件 |
| 2 | =a=0,A1.max(a=if(price>price[-1],a+1,0)) |
| 再比如,找出销售额累计占到一半的前 n 个大客户,并按销售额从大到小排序: |
| A | B | |
|---|---|---|
| 1 | //解析文件 | |
| 2 | =A1.sort(amount:-1) | /销售额逆序排序 |
| 3 | =A2.cumulate(amount) | /计算累计序列 |
| 4 | =A3.m(-1)/2 | /最后的累计即总额 |
| 5 | =A3.pselect(~>=A4) | /超过一半的位置 |
| 6 | =A2(to(A5)) | /按位置取值 |
跨数据源计算。SPL 支持多种数据源,除了结构化数据文件,还能计算各类数据库,Hadoop、redis、Kafka、Cassandra 等各类 NoSQL。各类数据源之间可以直接进行跨源计算,比如 xls 和 txt 的关联计算:
=join(T("D:/Orders.xlsx"):O,SellerId; T("D:/Employees.txt"):E,EId)
易于应用集成
方便易用的 JDBC 接口。简单的 SPL 代码可以像 SQL 一样,直接嵌入 JAVA:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="=T(\"D:/Orders.xls\").select(Amount>1000 && Amount<=3000 && like(Client,\"*s*\"))";
ResultSet result = statement.executeQuery(str);
计算外置降低耦合性。复杂的 SPL 代码可以先存为脚本文件,再以存储过程的形式被 JAVA 调用,可有效降低计算代码和前端应用的耦合性。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = conn.prepareCall("{call scriptFileName(?, ?)}");
statement.setObject(1, "2020-01-01");
statement.setObject(2, "2020-01-31");
statement.execute();
SPL 是解释型语言,通过外置代码可实现热切换。解释型语言无须编译,修改后可立即执行,无须重启 JAVA 应用,可降低维护工作量,提高系统稳定性。
计算 txt\csv\json\xml\xls 时,可用的类库虽多,但都有各自的缺点。SPL 是基于 JVM 的开源程序语言,可解析各类规则或不规则的结构化数据文件,可统一地表达二维结构的数据和多层结构的数据,用一致的代码进行日常 SQL 式计算。SPL 有更丰富的字符串和日期函数,更方便的语法,具有更强的计算能力;提供了易于集成的 JDBC 接口,支持算法内置和外置,可有效降低系统耦合性,并支持代码热切换。
SPL资料

欢迎对SPL有兴趣的加小助手(VX号:SPL-helper),进SPL技术交流群
所属网站分类: 技术文章 > 博客
作者:java战神
链接:http://www.javaheidong.com/blog/article/472561/38b3fa8511859111242f/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力