

JVM中的垃圾回收机制【GC】
发布于2022-09-18 17:07 阅读(328) 评论(0) 点赞(5) 收藏(4)
GC – 垃圾回收机制
为什么要进行垃圾回收? 要回收哪些内存空间的垃圾? 怎么判定垃圾? 怎么回收垃圾?
本文将解决以上问题。
什么是GC
先简单介绍一下什么是垃圾回收。
我们知道,在我们日常写代码的时候,会经常申请内存资源:实例对象,类加载,创建变量等等。。
那么我们向操作系统申请来的这些内存资源,什么时候还给操作系统呢?
这就面临着两个问题:
- 如果内存释放的太早了
如果内存释放太早,我们的实例还需要使用,就会陷入非常尴尬的局面,这就好像我们平时在家马上要穿的衣服被妈妈洗了一样难受。。。 - 如果内存释放的太晚了
如果内存释放时机太晚,就很容易造成 “内存泄漏”,进一步引起 “内存溢出问题”。
综上述两点说明,我们需要明确一个时机去释放申请来的内存,也就是 “垃圾”,来避免出现以上问题,这就是 GC – 垃圾回收机制。
回收哪些垃圾
在了解我们要回收的 “垃圾” 是哪些部分之前,要先弄清楚 JVM 中总共有哪些部分。
JVM 内存划分
在 JVM 中,内存模型被划分为四大块,分别是:
- 程序计数器
- 栈
- 堆
- 方法区
这些模块根据所需完成的功能的不同而进行划分,下面一一介绍每个部分具体有什么功能。
程序计数器:
程序计数器是内存中最小的一块区域,他存放的是当前指令执行完,下一条执行的位置。
CPU 调度的基本单位是线程,线程在 CPU 上进行调度的时候就需要知道下一条指令的位置,所以每一个线程内都有一个程序计数器。
栈:
栈里存放的是方法调用已经方法内的临时变量、引用以及方法调用信息等等,每一次方法的执行都相当于进行了一次 “入栈” 操作,而方法执行结束,则相当于进行了一次出栈操作。
这里的栈虽然是 JVM 里的栈,但和数据结构中的栈的工作过程十分相似,也会有 “栈帧”,排序数据这些概念,并且这里的栈也是每个线程独有一份。
堆:
堆跟程序计数器和栈都不一样,一个进程中独有一个堆,单个进程内多个线程共享一个堆,他也是 JVM 中内存最大的一块空间。
我们平时使用关键字 “new”,new 出来的对象就全部在堆上,当然,对象实例中的成员方法也都在堆上。
注意,一个方法内的引用指向了一个对象,此时,这个方法是处于栈上,而这个对象是处于堆上的
PS:不是所有的引用都在栈上
方法区:
方法区中,存放的是类对象,静态成员,常量池等等。。
所谓类对象,就是类加载过程中,JVM 在内存上运行 .class 文件构成的对象,类对象中就描述了类中的信息,这些二进制指令,就存放于方法区中。
静态成员 -》 类成员
上述的 JVM 内存区域划分是一个大概的版图,具体 JVM 的内部到底是怎么划分实现的,是根据 JVM 厂商,版本号等等因素决定的。
介绍完上述内存区域划分,我们再来讨论 JVM 释放的内存到底是哪里的内存呢?
- 首先,程序计数器,作为最小的存在,他的作用是存放下一条要执行的指令,而他的长度也是固定的,不需要被释放,也就不需要用到 GC 了。
- 其次,栈这个东西,方法调用结束之后就连着函数栈帧一并销毁了,这其中就包括了方法内部新建的临时变量,引用等等,是自动释放的,也不需要用到 GC。
- 再者,堆作为 JVM 中最大的一块空间,里面放着 “各式各样” 的对象,有的对象不再被任何引用指向了,那么这个对象也就成了 “垃圾”,所以堆,是 GC 过程中的主要目标。
- 最后,方法区中的静态成员和常量是不需要被释放的,而类对象,是类加载过程得来的,他的释放也就对应着 “类卸载”,这个操作是非常低频的,几乎用不到 GC。
综上所述,GC 的目标,就只有堆和方法区两个,并且主要的矛头直逼 “堆”。
PS:垃圾回收的单位是对象,而不是字节。
为什么要进行垃圾回收?
垃圾回收是一件比较复杂的事情,那么为什么要进行垃圾回收呢?
这里就要介绍一个臭名昭著的问题 – “内存泄漏”
内存泄漏
在我们的机器上,内存资源是十分有限的 – 主要原因是贵~
所以操作系统在把内存分配出去之后一定要回收,否则就会导致机器上可用的内存资源越来越少,最后导致要申请新的内存资源时,没有内存可用,造成 “内存溢出”,这就是著名的 “内存泄漏” 问题。
各种语言的回收处理
在 C 语言中,申请的内存空间都要求程序猿自己手动释放,如果程序猿忘记释放了,那么这一部分内存空间就 “回不来了”,就会导致 “内存泄漏”。
在 C++ 中,虽然没有像 C 语言那样放任不管,但毕竟 C++ 是一门追求极致性能的语言,而垃圾回收机制是依赖运行时做出许多额外操作,来让内存资源自动释放,并且垃圾回收机制有两个致命缺陷:
- 需要消耗更多的资源
- 可能引入 STW 问题(影响程序运行的流畅性)
所以 C++ 没有引入 GC 机制,而是依赖了智能指针等机制减缓 “内存泄漏” 的问题。
现在市场是其他比较主流的编程语言,如:Java、python,go 等等,都引入了垃圾回收机制,来自动释放内存资源。
Rust 是一门强语法级语言,与 C++ 一样,是一门追求极致性能的编程语言,他会在编译阶段就排查出内存泄漏的可能,以此来防范内存泄漏问题。
JVM 的 GC 流程
JVM 中的 GC 流程分为两步:
- 判定垃圾
- 回收垃圾
判定垃圾
判定垃圾的方式主要有两种:
- 引入引用计数器(Python 等语言使用)
- 基于可达性分析(JVM 的处理方式)
这里先介绍基于可达性分析的操作,文末介绍引入引用计数器的方法及其缺陷。
在JVM 中,依赖基于可达性分析的操作,来确定某一个对象是否为 “垃圾”。
可达性分析:通过引入额外的线程,来定期的针对整个内存空间里的对象进行扫描,这个过程类似于深度优先遍历,找到几个起始点(GC Roots),从起始点开始扫描,把所有扫描到的对象给做上标记,这样一来,所有被标记过的对象就是可达的对象,而不可达的对象就认为是 “垃圾”。
举一个栗子:这里有一颗树
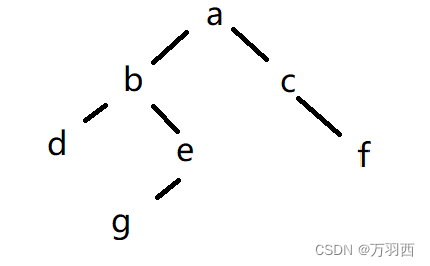
此时如果把 a 节点作为 GC Roots 进行遍历,那么就可以遍历到 a~g 所有的节点,也就意味着此时所有的节点对象都是可达的。
但是如果我们把节点 c 的 next 置为 null,也就是:c.right == null,结果如下:
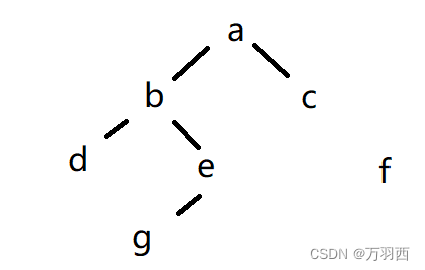
此时的 f 节点也就是不可达的了,也就被我们判定是 “垃圾”。
一般来说 GC Roots 有以下几种:
- 栈上的局部变量
- 常量池中的引用指向的对象
- 方法区中静态成员指向的对象
如果对象特别多,也就意味着一次 GC 扫描的对象数量会很多,那么这一次遍历就会变得很慢,所以其实 GC 的开销还是很大的。
总结: GC 中判定垃圾的标准依据就是,你作为一个对象,如果还有引用指向你,那么你就不是垃圾,如果没有了,那你就是 “垃圾”。
释放垃圾
判定完对象是否为垃圾之后,就要开始释放垃圾了。
而释放垃圾,有以下三种策略:
- 标记 - 清除
- 复制算法
- 整理清除
接下来我们一一解释。
- 标记 - 清除
这种策略非常的简单粗暴,所谓标记,也就是上面刚刚提到了可达性分析的过程,但是这里标记的可就不是那些可达的对象了,而是那些被认定为是 “垃圾” 的对象。
将 “垃圾对象” 做好标记之后,直接释放内存,还给操作系统。
这种方式有一个非常大的弊端,看下图:

假设白色的是刚刚被释放的内存空间,而黑色的是继续在用的对象,这样一看就会发现,这不就是 “内存碎片” 问题嘛。
我们知道,我们的程序在向操作系统申请内存的时候,都是申请一段连续的存储空间,但是你释放空间时释放的这么零零散散,就很有可能产生内存溢出问题。
比如说,我想要向操作系统申请 1G 的内存,虽然操作系统中这些间断的内存加一起正好有 1G,但依然无法分配,所以这个问题就会非常严重的影响程序的运行。
- 复制算法
复制算法很好的解决了 “标记 - 清除” 的问题,他的做法是,把内存空间分为两部分。
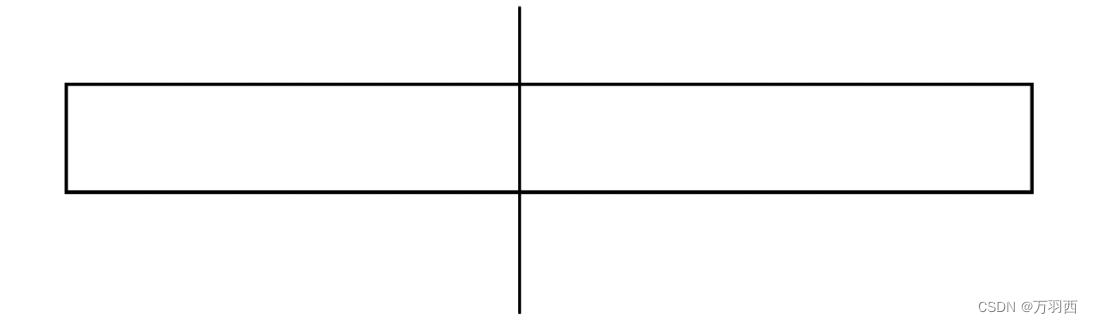
这些内存空间,用一半,丢一半。
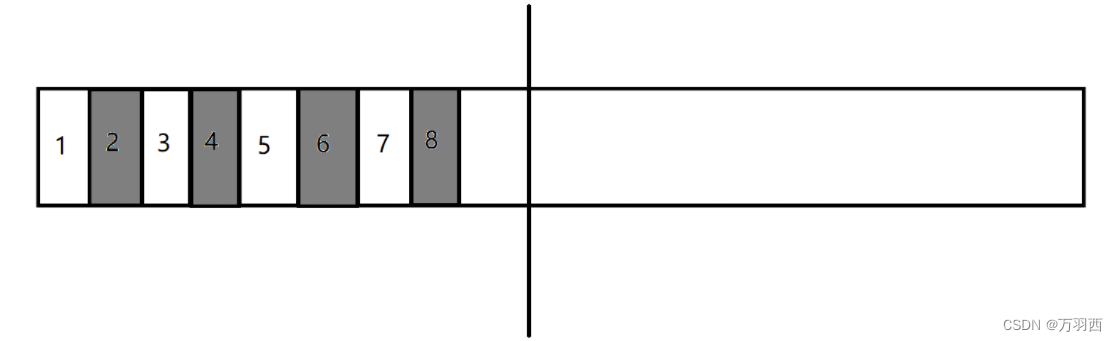
假设,黑色标记的是垃圾,那么我就把白色的对象复制到内存条的右边,然后把左边的内存空间整体释放。
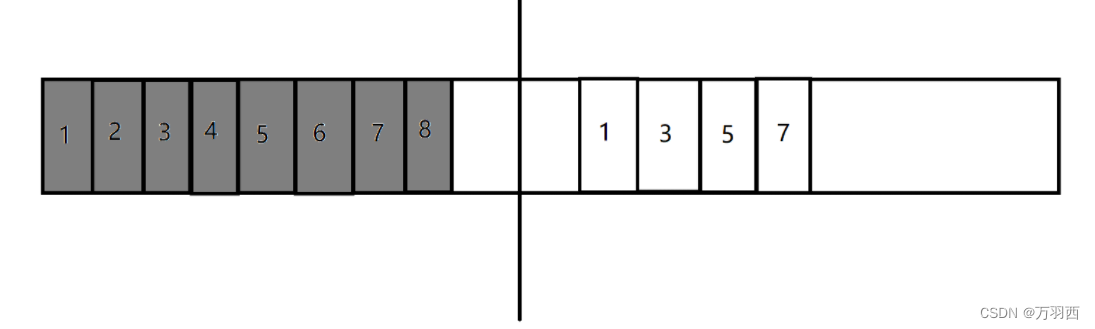
这样就很好的解决了 “内存碎片” 的问题了。
注意:
这里对象的地址变了也没有关系,JVM 内部会自适应的改变引用所指对象的地址。
但是,复制算法依然存在一些问题:
- 显而易见的就是,内存的空间利用率较低,每次都要牺牲一般的空间用来进行复制使用。
- 如果一次 GC 扫描发现的垃圾较少,这就意味着要拷贝的要使用的对象很多,开销较大。
- 整理 - 清除
整理 - 清除策略是在复制算法上又加了一些改进。
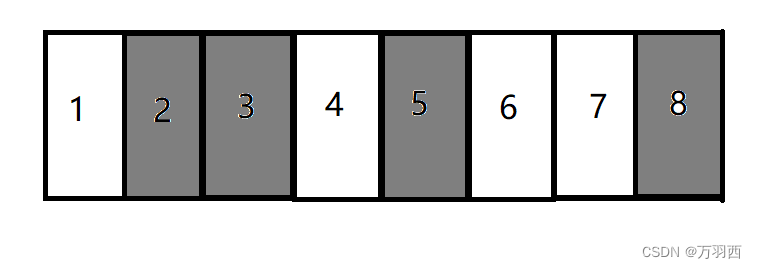
同样的,这里的黑色表示被标记为垃圾的对象。
这里做一个类似于顺序表删除中间元素一样的操作,把后面的有效对象移动到前面来。
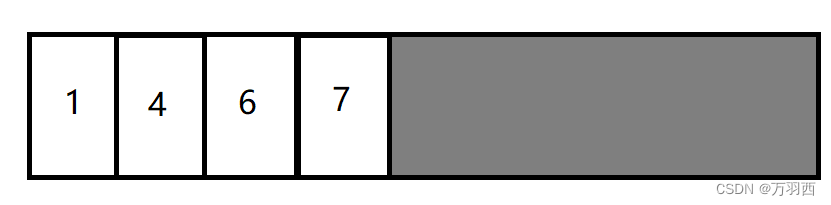
这样就可以把后面的空间整体释放了。
这样做虽然解决了空间利用率的问题,但依然无法解决复制移动的开销。
所以接下来要介绍 JVM 中的处理,JVM 把上面几种方式进行结合,使用 “分代回收” 的方式进行处理。
分代回收:
先给出一个定义,每一个对象,都有自己的 “年龄”,而这个年龄是随着 GC 扫描轮数去增长的,如果经过一轮 GC 扫描,还没有被释放掉,就认为这个对象年龄增长一岁。
再针对年龄不同的对象,分别进行处理。
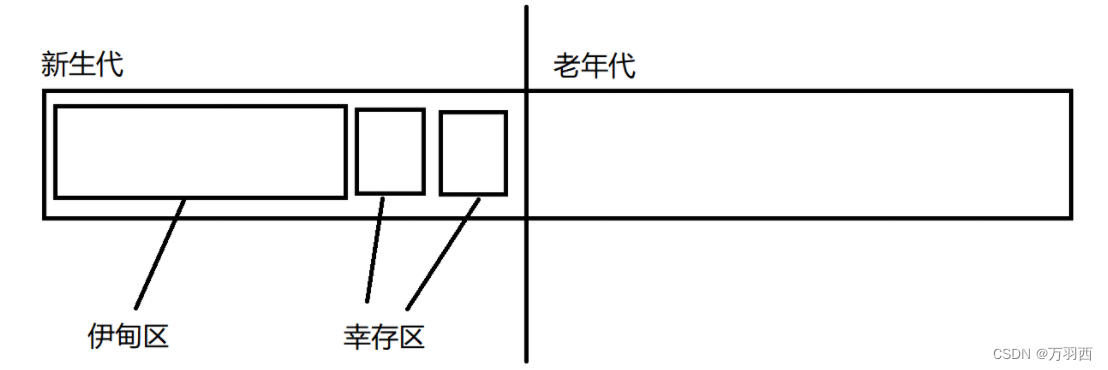
步骤:
- 所有刚创建出来的对象,全都放进 “伊甸区”,是一个比较大的内存空间
- 因为大部分对象其实都是 “朝生夕死” 的,所以我们认为,如果一个对象撑过了一轮 GC 扫描,则他算是比较 “命大”,就把他移入 “幸存区”(通过复制算法)
- 在伊甸区被 GC 释放采用 “整理 - 清除” 的策略
- 在后续几轮的 GC 扫描中,每一轮都会在幸存区内释放掉一部分对象,而剩下依然没被释放的对象,就在两个幸存区空间内来回拷贝。
- 在持续若干轮的 GC 扫描之后,还没有被释放掉的 “硬骨头”,就会被移入老年代
- 老年代的特点:里面的对象基本上都是年龄比较大的,而我们认为,一个对象越老,那他被释放的概率就越低(要死早死了),所以,在老年代内的 GC 扫描频率会大大降低。
以上就是分代回收的整个过程,但是还有个特例(可能他爸是李刚),有一类对象,可以直接进入老年代,那就是 “大对象”(其实就是内存占用比较多的对象),因为针对大对象进行复制算法的话,开销太大,所以直接移入老年代比较稳妥。
总结
以上就是在 JVM 中整个垃圾回收的过程,垃圾回收,分为两部分:判断垃圾 + 回收垃圾。
判断垃圾依靠:可达性分析
回收垃圾依靠:(标记 - 清除,复制算法,整理 - 清除)-> 分代回收
文末再介绍一种 Python 中的判定垃圾方式。
最后,希望本文可以对大家有帮助~
PS: Python 中如何判定垃圾
在 Python 中,并没有像 JVM 一样依赖可达性分析进行判断,而是依靠引入一种类似于程序计数器一样的东西,姑且给它取个名字 – “引用计数器”。
他的处理是,给每一个对象,都额外分配一块内存,记录当前对象被多少个引用给指向了。
比如:
Test t = new Test();
Test t2 = t; // t 和 t2 都是指向这个对象的引用

此时的 new Test()对象被 t 和 t2 两个引用指向了,所以引用计数为 2。
如此,当引用计数不为 0 时,则认为他是有效对象,而当引用计数为 0 时,就认为他是垃圾。
但是,这种方式有两个缺陷:
- 空间利用率较低
- 可能造成内存泄漏
解释:
-
假设,引用计数器的固定大小为 4 字节,如果我的对象占空间大小为 100 字节,那这 4 字节微不足道,但是如果这个对象本身只有 4 个字节,那就意味着要多消耗一倍的空间来完成引用计数,此时的空间利用率就很低了。
-
假设一种情况如下:
class Test {
Test t = null;
}
Test t1 = new Test();
Test t2 = new Test();
t1.t = t2;
t2.t = t1;
此时的 t1 和 t2 两个引用分别指向了对方的对象。

接下来执行:
t1 = null;
t2 = null;

此时的 t1 和 t2 都置为了空,但是这两个对象都被对方互相指向了…这就很尴尬,他们也释放不掉,也没有引用指向,就像被孤立的小岛…
所以,Python 里也不只是依靠引用计数,还依赖了其他机制配合。
但是这里就不细讲拉~ 拜拜~
原文链接:https://blog.csdn.net/Aaron_skr/article/details/126310050
所属网站分类: 技术文章 > 博客
作者:coding
链接:http://www.javaheidong.com/blog/article/504372/06d3e5343b1c4a144920/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力