

JavaEE进阶常见面试问题 - 细节狂魔
发布于2022-09-18 17:04 阅读(701) 评论(0) 点赞(17) 收藏(2)
文章目录
- 前言
- 1.常⻅的 ORM 框架有哪些?
- 2.[Bean容器/Ioc容器的理解](https://blog.csdn.net/DarkAndGrey/article/details/125621681?spm=1001.2014.3001.5501)
- 3.[IoC/DI的理解](https://blog.csdn.net/DarkAndGrey/article/details/125621681)
- 4.[Spring中的单例bean的线程安全问题 - Bean 的作用域问题](https://blog.csdn.net/DarkAndGrey/article/details/125785133)
- 5.[Spring中的bean的作⽤域有哪些?](https://blog.csdn.net/DarkAndGrey/article/details/125785133)
- 6.FactoryBean和BeanFactory
- 7.[Bean的⽣命周期](https://blog.csdn.net/DarkAndGrey/article/details/125785133)
- 8.Spring三级缓存的理解
- 9.[AOP的理解](https://blog.csdn.net/DarkAndGrey/article/details/126292695)
- 10.[Spring事务中的隔离级别有哪⼏种?](https://blog.csdn.net/DarkAndGrey/article/details/126406507)
- 11.Spring事务中有哪⼏种事务传播⾏为?
- 12.[SpringMVC的流程](https://blog.csdn.net/DarkAndGrey/article/details/125962400)
- 13.[Mybatis中,#{}和${}的区别](https://blog.csdn.net/DarkAndGrey/article/details/126103652)
- 14.[Mybatis中如何⼀对⼀、⼀对多关联](https://blog.csdn.net/DarkAndGrey/article/details/126103652)
- 15.SpringBoot ⾃动配置原理
前言
关于 JavaEE 进阶 的内容,在上篇Spring事务和事务传播机制已经讲完了。
这篇文章,不光为了你们,也是为了我自己。
这篇问斩,主要讲解 JavaEE 进阶,在面试可能遇到问题。
属于 面试的复习资料。
注意!本文大部分都是超链接,看到不懂的,或者说印象不深的,可以点过去复习。
1.常⻅的 ORM 框架有哪些?
当我们看到哦这个问题的时候,思考一下:什么是 ORM 框架?
ORM:Object Relational Mapping - 对象关系映射
ORM 框架:就是把 Java 中的 对象 与 数据库中的数据表映射起来 的 框架。
1、MyBatis
Mybatis是⼀种典型的半⾃动的 ORM 框架.
所谓的半⾃动,是因为还需要⼿动的写 SQL 语句,再由框架根据 SQL 及 传⼊数据来组装为要执⾏的 SQL。优点为:
1、因为由程序员⾃⼰写 SQL,相对来说学习⻔槛更低,更容易⼊⻔。
2、 更⽅便做 SQL的性能优化及维护。
3、 对关系型数据库的模型要求不⾼,这样在做数据库模型调整时,影响不会太⼤。适合软件需求变更⽐较频繁的系统,因此国内系统⼤部分都是使⽤如 Mybatis 这样的半⾃动 ORM 框架。
缺陷为:
不能跨数据库,因为写的 SQL 可能存在某数据库特有的语法或关键词
2.Hibernate
虽然我没讲(没学),但是!对它还是要有基本的了解。
Hibernate是⼀种典型的全⾃动 ORM 框架,所谓的全⾃动,是 SQL 语句都不⽤在编写,基于框架的 API,可以将对象⾃动的组装为要执⾏的 SQL 语句。其优点为:
1、 全⾃动 ORM 框架,⾃动的组装为 SQL 语句。
2、可以跨数据库,框架提供了多套主流数据库的 SQL ⽣成规则。
其缺点为:
学习⻔槛更⾼,要学习框架 API 与 SQL 之间的转换关系
对数据库模型依赖⾮常⼤,在软件需求变更频繁的系统中,会导致⾮常难以调整及维护。可
能数据库中随便改⼀个表或字段的定义,Java代码中要修改⼏⼗处。
很难定位问题,也很难进⾏性能优化:需要精通框架,对数据库模型设计也⾮常熟悉。Hibernate 是允许 我们 使用 HQL(Hibernate Query Language的缩写)语言。
也就是说:Hibernate有着自己一套语言规则(语法)。
让我们按照它的语法 进行 操作的。
那么,可想而知:我们在进行一些复杂操作的时候,我们是需要学习一门新的语言!
所以,它很复杂、!
虽然,它实现一个 简单的 CURD,很容易。
但是!如果你想更熟练操作它 实现 复杂的业务,非常难!!!
这也是为什么国内使用的最多的是 MyBatis 的原因。
Hibernate 虽然入门简单,但是!想精通非常难!
MyBatis 相对来说,就很平滑,很灵活!
SQL 是我们写的嘛!只有SQL没有语法问题,就能操作数据库。
所以说,很灵活,更可控!
而 Hibernate 帮我们封装成了 黑匣子(对程序员来说:底层运行是不可见的)。
这样就会导致 我们无法得知 它自动生产的 HQL 是否正确。
这也就表现出 Hibernate 的 不可控性。
还有我国还在处于发展阶段,变化比较大,相对来说需求的种类就非常多。
反正,国内的需求,层次不穷,千奇百怪!
各种稀奇古怪的需求都有。【就比如 手机壳 的那个梗】
我们程序员最大的敌人,不是用户,而是产品经理,奇怪的需求,多半是它提出来的。
不过呢,也不能怪他(她)。
毕竟,在国内,我就没有听过:有机构 和 公司 对 产品经理 进行培训的。
而且,大部分产品经理,他是不懂技术的。
他不知道哦他提出的需求,实现起来有多复杂。
他只是感觉 这个功能 能够 提升用户体验,于是,他提出来了。
而产品经理提出的需求,是我们程序的源头,就是说:我们要根据 需求 来设计程序。
所以说:我们开发人员 和 产品之间 交流 是非常多的!
大部分都是围绕需求进行讨论,讨论需求有没有实现的必要,或者实现起来有多复杂。
于是,MyBatis 的 灵活性 就能 很好的去适应 多变的需求。
这也是为什么国内使用的最多的 ORM 框架 是 MyBatis 的原因。
当然也不能说 Hibernate 就完全没有优点。
我一开始还给列出两个优点。
Hibernate 就是在单表查询的时候,很简单,容易上手。这算一个。
其中最突出的优点:
在进行数据库转换的时候,比如: MySQL 转换成 SqlServer ,或者把 MySQL 替换成 Oracle 的时候,使用 Hibernate 非常简单!!!
几乎不需要改一行代码!!!
因为 我们使用 是 Hibernate 指定的 HQL 语法。
就像我们的 JDBC 编程,不用去关注底层的数据库是哪一个,我们只需要使用 JDBC 提供语法去操作就可以,底层它会帮我们去生成对应 SQL。
Hibernate 也是这样去做的,我们只需要会是使用它提供的语法,至于底层的数据库,不要我们去关心,它会帮我们去处理,生成对应的 SQL 语句。
所以说: Hibernate 在进行替换数据库的时候,几乎是没有成本的!!!
我们的MyBatis 就没有那么幸运了!
因为 MyBatis 里面的重点是需要我们自己去写 SQL 语句。
虽然我们使用的是 TSQL97,或者是 99 的标准。
但是!不同的数据库,有这不同的执行行为!
比如:SqlServer 里面的一个 分页查询 和 MySQL,就完全不一样!
SqlServer 的 分页查询,它是 select top + 条数 + * from + 表名。
而 MySQL 的分页查询使用的是 limit + 偏移量 + 多少条数据 ,也就是 左开右闭。
也就是说:我们在使用 MySQL的时候,将 MySQL 替换成 其它的数据库的时候,成本非常非常大!
我们要把 所有的 SQL 语句 都检查一遍,确定要修改的SQL,然后,开始进行一句一句的修改 SQL 。非这么做不可!因为 你SQL,底层的数据库得识别啊!不然怎么操作数据库啊!
所以,这个工作量是极其大的。
但是呢!这种事情发生的概率是非常小!
毕竟,是一件麻烦事。

2.Bean容器/Ioc容器的理解
Spring容器主要是对 IoC 设计模式的实现,主要是使⽤容器来统⼀管理Bean对象,及管理对象之间的依赖关系。
创建容器的API主要是BeanFactory和ApplicationContext两种:1、 BeanFactory是最底层的容器接⼝,只提供了最基础的容器功能(bean的管理 和 实例化):Bean 的实例化和依赖注⼊,并且使⽤懒加载的⽅式,这意味着 beans 只有在我们通过 getBean() ⽅法直接调⽤它们时才进⾏实例化。
2、 ApplicationContext(应⽤上下⽂)是BeanFactory的⼦接⼝,与 BeanFactory 懒加载的⽅式不同,它是预加载,所以,每⼀个 bean 都在 ApplicationContext 启动之后实例化。
3、 ApplicationContext 除了基础功能,还添加了很多增强:
3.1、整合了Bean的⽣命周期管理
3.2、i18n国际化功能(MessageSource)
3.3、载⼊多个(有继承关系)上下⽂ ,使得每⼀个上下⽂都专注于⼀个特定的层次,⽐如应⽤的web层
3.4、事件发布响应机制(ApplicationEventPublisher)
3.5、AOP
3.IoC/DI的理解
概念
IoC (Inversion of Control) 即控制反转,是⾯向对象编程中的⼀种设计原则。主要是通过第三⽅IoC容器,对Bean对象进⾏统⼀管理,及组织对象之间的依赖关系。
获得依赖对象的过程,由原本程序⾃⼰控制,变为了IoC容器来主动注⼊,控制权发⽣了反转,所以叫做IoC,控制反转。
IoC⼜叫做DI:由于控制反转概念⽐较含糊(可能只是理解为容器控制对象这⼀个层⾯,很难让⼈想到谁来维护对象关系),相对 IoC ⽽⾔,依赖注⼊实际上给出了实现IoC的⽅法:注⼊。
所谓依赖注⼊(DI),就是由 IoC 容器在运⾏期间,动态地将某种依赖关系注⼊到对象之中。
依赖注⼊(DI)和控制反转(IoC)是从不同的⻆度的描述的同⼀件事情,就是指通过引⼊IoC容器,利⽤依赖关系注⼊的⽅式,实现对象之间的解耦。
实现⽅式
DI是IoC的实现⽅式之⼀。⽽DI 的实现⽅式主要有两种:构造⽅法注⼊和属性注⼊。(Setter 注入,用的很少,效率太低了。)
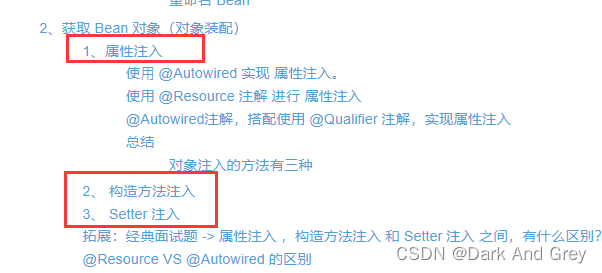
实现原理
主要依赖反射及ASM字节码框架实现(字节码框架操作字节码更为⾼效,功能更强⼤)。
4.Spring中的单例bean的线程安全问题 - Bean 的作用域问题
⼤部分时候我们并没有在系统中使⽤多线程,所以很少有⼈会关注这个问题。
单例bean存在线程问题,
主要是因为当多个线程操作同⼀个对象的时候,对这个对象的⾮静态成员变量的写操作会存在线程安全问题。
因为 Spring 默认是 单例模式。
每个 Bean 在整个 Spring 中只有⼀份,也就说:资源是全局共享的。
那么当其他⼈修改了这个值之后,那么另⼀个⼈读取到的就是被修改的值。
有两种常⻅的解决⽅案:
1.在bean对象中尽量避免定义可变的成员变量【全部定义成常量】(不太现实,因为很多时候,都是需要动态的赋值)。
2.在类中定义⼀个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的⼀种⽅式)。
ThreadLocal 有三种方法:Set,Get,Remove,它就相当于给每个线程设置了单独的变量、也就是说每个线程操作的变量都是自己的。
都操作的自己的变量了,那还存在线程安全的问题嘛?没有!
5.Spring中的bean的作⽤域有哪些?
1.singleton:唯⼀bean实例,Spring中的bean默认都是单例的。
2.prototype:每次请求都会创建⼀个新的bean实例。
3.request:每⼀次HTTP请求都会产⽣⼀个新的bean,该bean仅在当前HTTP request内有效。
4.session:每⼀次HTTP请求都会产⽣⼀个新的bean,该bean仅在当前HTTP session内有效。
5.application:在⼀个应⽤的Servlet上下⽂⽣命周期中,产⽣⼀个新的bean
6.websocket:在⼀个WebSocket⽣命周期中,产⽣⼀个新的Bean
6.FactoryBean和BeanFactory
BeanFactory是Spring容器的顶级接⼝,所有Bean对象都是通过BeanFactory也就是Bean容器来进⾏管理。
FactoryBean是实例化⼀个Bean对象的⼯⼚类,实现了 FactoryBean 接⼝的Bean,根据该Bean的ID从BeanFactory中获取的实际上是FactoryBean中 getObject() ⽅法返回的对象,⽽不是FactoryBean本身,如果要获取FactoryBean对象,请在id前⾯加⼀个&符号来获取。我们所有的 Bean 都是来自于 FactoryBean 的。
但是,FactoryBean 中 的 Bean,会交由 BeanFactory 来管理。
FactoryBean 就像是 布置作业的老师,所有的作业(bean)都来自老师。
学习委员就是 BeanFactory,所有的作业(Bean)都由她来管理。
FactoryBean 和 BeanFactory 之间的关系,就像 线程工厂 和 线程池 之间的关系是一样的。
线程工厂(ThredFactory) 和 线程池(ThreadPoolExecutor),这两个我只是在案例中稍微提了一下。
我们所有的线程池在创建的时候,都可以设置一个 ThreadFactory (线程工厂)。
如果我们不设置 线程工厂的话,它会根据默认的线程工厂来创建线程。
但是!这个这个线程创建好了之后呢,它会放到线程池里面(ThreadPoolExecutor)。
所以,BeanFactory 就像是 ThreadPoolExecutor,FactoryBean 就像是 ThreadFactory。

7.Bean的⽣命周期
这里说的比较专业一些,文章中的更通俗易懂。
1、实例化Bean:通过反射调⽤构造⽅法实例化对象。
【给 Bean 分配 内存空间】
2、 依赖注⼊:装配Bean的属性(Bean注入)
3、 实现了Aware接⼝的Bean,执⾏接⼝⽅法:如顺序执⾏BeanNameAware、BeanFactoryAware、ApplicationContextAware的接⼝⽅法。
【执行各种通知(各种Aware)】
4、 Bean对象初始化前,循环调⽤实现了BeanPostProcessor接⼝的预初始化⽅法(postProcessBeforeInitialization)
【执行初始化的前置方法】
5、 执⾏Bean对象初始化⽅法
【执行构造方法: @PostConstruct , init-method】
6、 Bean对象初始化后,循环调⽤实现了BeanPostProcessor接⼝的后初始化⽅法(postProcessAfterInitialization)
【使⽤ Bean】
7、容器关闭时,执⾏Bean对象的销毁⽅法
【销毁 Bean:@PreDestroy,DisposableBean ,destroy-method】
8.Spring三级缓存的理解
这个问题或者换个问法:Spring是如何解决循环依赖的?
答案即是Spring的三级缓存这里我简单的说一下缓冲:
一般系统里面都会去加缓存,加缓冲的目的和意义很明确!
就是为了 提高查询效率的!
假设,我们现有一个数据库,而且里面的数据非常多! 几亿 ~ 几十亿条数据。
然后呢,我们在查询这些数据的时候,我们需要花费 60s 的时间。
也就是说:我们的每一次查询,都需要 60s 的时间。
但是!我们可以做一件事:
可以把查询到的结果放到缓存当中,缓存在存储的数据的时候,通常是以 key-value 的形式来存储的。
所以,它的一个时间复杂度是O(1).,执行效率是非常高的!(毫秒级)
我们就这个耗费60s得到的数据 放到缓冲中,等到下一次查询的时候,就不用去查询数据库了,直接去查缓冲。
缓冲查询的时间是毫秒级的,之前 60 s 才能获取的数据,现在只需要 10 ms,查询效率的提升是非常巨大的!
缓存存在的目的:提高查询的效率。
那好,Spring的三级缓存起着什么作用呢?
为什么要使用三级缓存呢?
Spring的 三级缓存有点不一样 ,它的目的 和刚才我们说的缓存 是不一样的。
它的目的是:解决循环依赖的问题。
什么是循环依赖
简单说,就是A对象依赖B对象,B对象⼜依赖A对象,类似的代码如下:
给你一种 链表的 “环”的感觉。
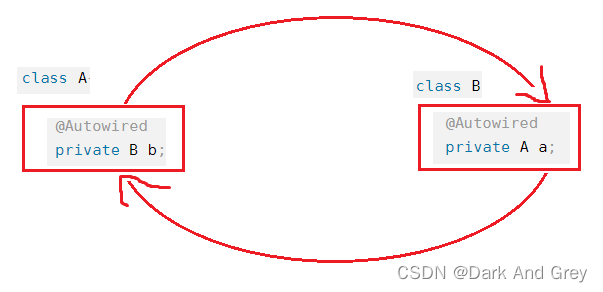
@Component
public class A{
@Autowired
private B b;
}
@Component
public class B{
@Autowired
private A a;
}
注意!这不是死锁!叫法不一样!
使用三级缓存,就可以解决这个问题。
循环依赖,在Sring里面是比较难的问题。
这也是为什么前面的文章没有讲它的原因。在 Spring 6 之后,也就是说在 Spring Boot 3.0之后,也就是今年12月份将要发布的新版本里面,会将这个循环依赖的功能设置成默认为关闭的状态。
也就是说:
这个代码,在 spring 6 之前的版本里面这样写没问题,不会报错。
但是!在Spring Boot 3.0 之后,这样去写,会报错!
原因就是 循环依赖 本来就不是正规用法,但是之前确实存在着这样的问题。
存在这个问题,官方就肯定是要解决的。
Bean的⽣命周期回顾
1、 启动容器:加载Bean
2、 实例化Bean对象
3、 依赖注⼊:装配Bean的属性
4、 初始化Bean:执⾏aware接⼝⽅法、预初始化⽅法、初始化⽅法、后初始化⽅法
5、 关闭容器:销毁Bean
在以上第四个步骤执⾏完毕,才算⼀个初始化完成的Bean,也即Spring容器中完整的Bean对象。
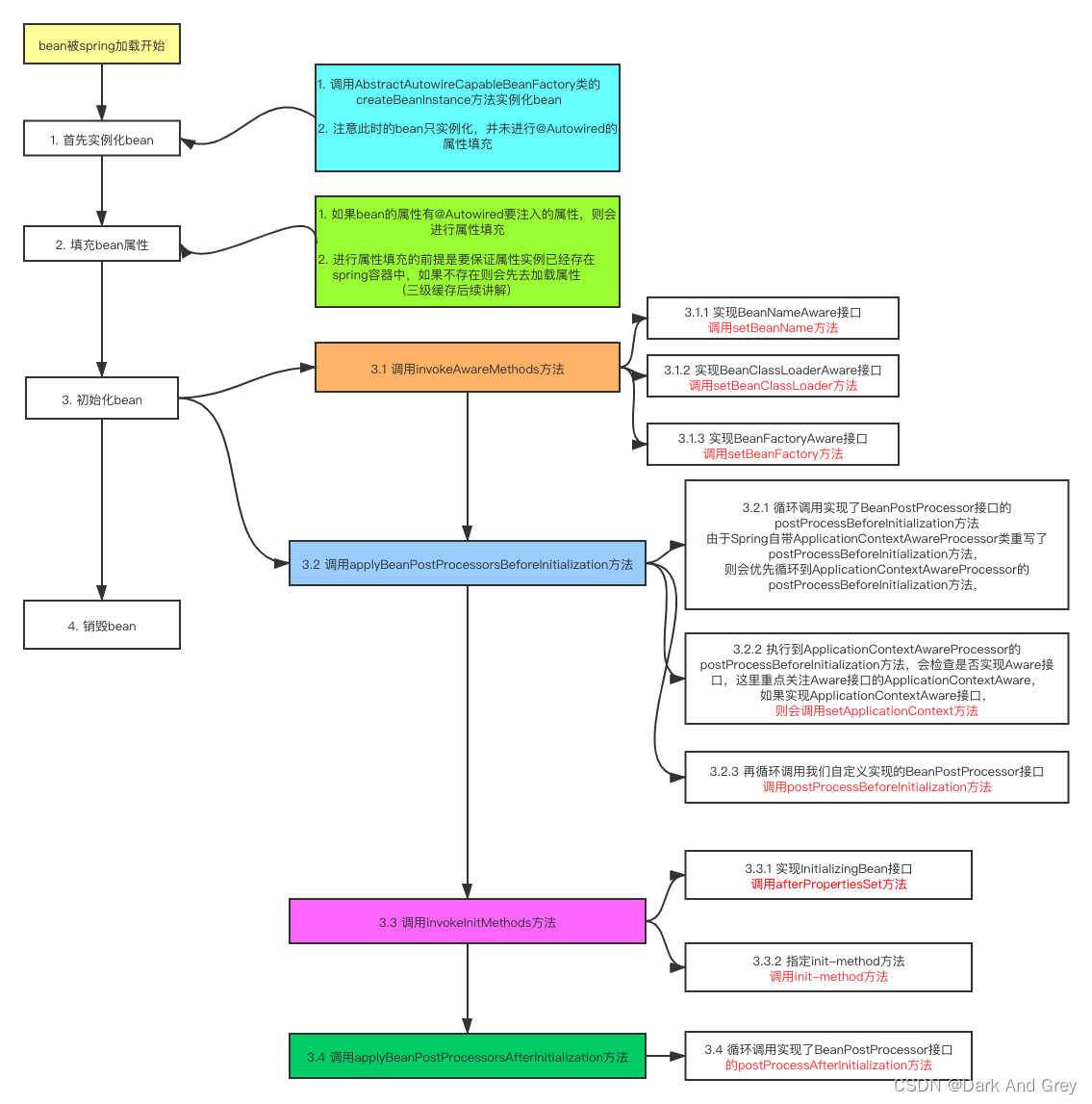
循环依赖的问题
Spring容器保存Bean的⽅式,是采取缓存的⽅式:使⽤ Map<String, Object> 的结构,key为Bean的名称,value为Bean对象。需要使⽤时直接从缓存获取。
假如A、B互相依赖(循环依赖):
1、容器中没有A对象,实例化A对象
2、装配A中的B对象,发现B在容器中没有(B 还没开始创建),需要先实例化B
3、实例化B对象
4、装配B中的A对象,发现A在容器中没有 ( 此时,A还没有创建成功 ),需要先实例化A
5、重复第⼀个步骤
这就套娃了, 你猜是先 StackOverflow 还是 OutOfMemory ?
Spring怕你不好猜,就先抛出了 BeanCurrentlyInCreationException
PS:
Bean会依赖某些注⼊的Bean来完成初始化⼯作
由于Spring⽀持构造⽅法注⼊,属性 / Setter注⼊的⽅式,所以不能简单的先把所有对象全部实例化,放到缓存中,再全部执⾏初始化。
原因很简单,此时所有对象的引⽤都可以获取到,但属性都是null,执⾏初始化甚⾄构造⽅法都可能出现空指针异常。
那么我们说Spring能解决循环依赖,也不是所有的情况都可以解决,只有以下情况才⽀持。


Spring⽀持循环依赖的场景
在Spring容器中注册循环依赖的Bean,必须是单例模式,且依赖注⼊的⽅式为属性注⼊。
原型模式及构造⽅法注⼊的⽅式,不⽀持循环依赖。以下为说明:原型模式(prototype)的Bean:原因很好理解,创建新的A时,发现要注⼊原型字段B,⼜创建新的B发现要注⼊原型字段A…
还是典型的套娃⾏为…
基于构造器的循环依赖,就更不⽤说了,官⽅⽂档都摊牌了,你想让构造器注⼊⽀持循环依赖,是不存在的,不如把代码改了。
那么默认单例的属性注⼊场景,Spring是如何⽀持循环依赖的?
Spring解决循环依赖
Spring是使⽤三级缓存的机制来解决循环依赖问题,以下为三级缓存的定义:
对于上面的描述,还需要补充一点:
三级缓存同一时间,只能有一个缓存在工作(只能存一分数据),其它缓存都会被删除掉。
比如:Bean 存储到一级缓存里面,那么二级和三级缓存就会被删掉。
同理,存储到二级缓存,那么 一级 和 三级缓存 就会被删掉。
如果存储的是三级缓存,那么 一 和 二级缓存 就会删除。
这么说吧:
查的时候,是一二三的顺序查的。
但是!存的时候,是按照 三二一的顺序存储的。
因为上面的缓存存储的数据是包含下面缓存存储的数据。
举个例子:
1级缓存就好比一个豪车,3级缓存就好比是 小轿车。
豪车 包含了 小轿车 的所有功能,并且还多出一些功能。【查询的时候】
而我们在买车(存Bean)的时候,都是按照 便宜车(一级) 到 贵车(3级) 看起的。
因为大家手头都不是很富裕,好车贵的太贵了。。。。回到原先例子,我们来分析它是执行的详细过程
当我们的 A 需要填充 B 属性了,它就会按照 一二三的顺序,去查看有没有一个 B 类型 的 Bean,代码还没有执行到 B 类,所以B 的 Bean 是不可能在 三级缓存存在的。这个时候,它就会去创建 B 了。
创建 B 的时候,就会把 A 放在 二级缓存中。
然后,创建B的时候,B 开始实例化,属性注入。。。
当属性注入的时候,发现 B 里面 引用了 A,所以,它又会去 按照 一二三的顺序 查找 A。
在 二级缓存中 找到了 A ,找到了之后,就把 B 里面的 A 属性的引用地址 指向 这里面的 A 对象,虽然 A 对象是一个半成品,但是我们只是把地址指向它了。
这就像风险投资一样,投资那些还在发展中的“潜力股”。
然后, 就继续做我(B)的事了,进行初始化。
初始化完了之后,就会把 B 的 Bean 放到 一级缓存中。
此时,我们A对象就可以继续执行了,从 一级缓存中拿到 B 的 Bean 了。
然后,A 开始 初始化,接着存入一级缓存。
虽然,我们的程序出现了像 多线程一样的,类似于死循环的问题。
在Spring中叫做循环依赖,但是!大家也看到了 三级缓存 是可以解决循环依赖的问题的!那么,在抛出一个问题,为什么要三级缓存,而不是二级 和 一级呢?
这就和 TCP 三次握手是一样的情况。
使用 二级缓存是不行的,必须要使用三级的缓存才可以解决 循环依赖的问题。
理由1:这三个缓存中,各自存储的东西都是不一样的。
当一个Bean刚开始实例化的时候,是存放在三级缓存中的;
当我们的Bean加载到一半的时候,就会存放在 二进缓存中,将一级缓存的数据删除。
而且,二级缓存又可以分成2个部分,所以 二级 和 三级 是不能合并的。
还有,一个完整 Bean 独享,肯定要单独 放在一个地方(一级),这是无法避免的。
所以, 三级缓存,一级都不能少!
但是!如果二级缓存中没有 AOP 这一个环节,就是单纯的存储 半成品的Bean 的话,那么 二级 和 三级 缓存 是可以合并的!
也就是说:二级缓存 不能解决 循环依赖 的 主要问题就在于 二级缓存中 多了 AOP 环节,导致二级缓存复杂化了,需要单独的缓存。因此 存储工厂类 只能独占一个缓存。
而 完整Bean又需要一个单独的和缓存来存放。
所以,不得不需要 三级缓存,而不是 二级 和 一级缓存。
Spring 中的三级缓存说白了,就是:3个 HashMap。
并且,它在Spring原码的时候,就是使用的 Map。
理由前面也说过:使用 Map 图的就是它的查询效率!三级缓存的源码⻅ DefaultSingletonBeanRegistry :
以下是部分说明:
三级缓存singletonFactories中保存的是ObjectFactory对象(Bean⼯⼚),其中包含了BeanName,Bean对象,RootBeanDefinition,该⼯⼚可以⽣成Bean对象。
由于Bean可能被代理,此时注⼊到其他Bean属性中的也应该是代理Bean。
单例模式的A、B循环依赖执⾏流程如下:【这个更细一点】
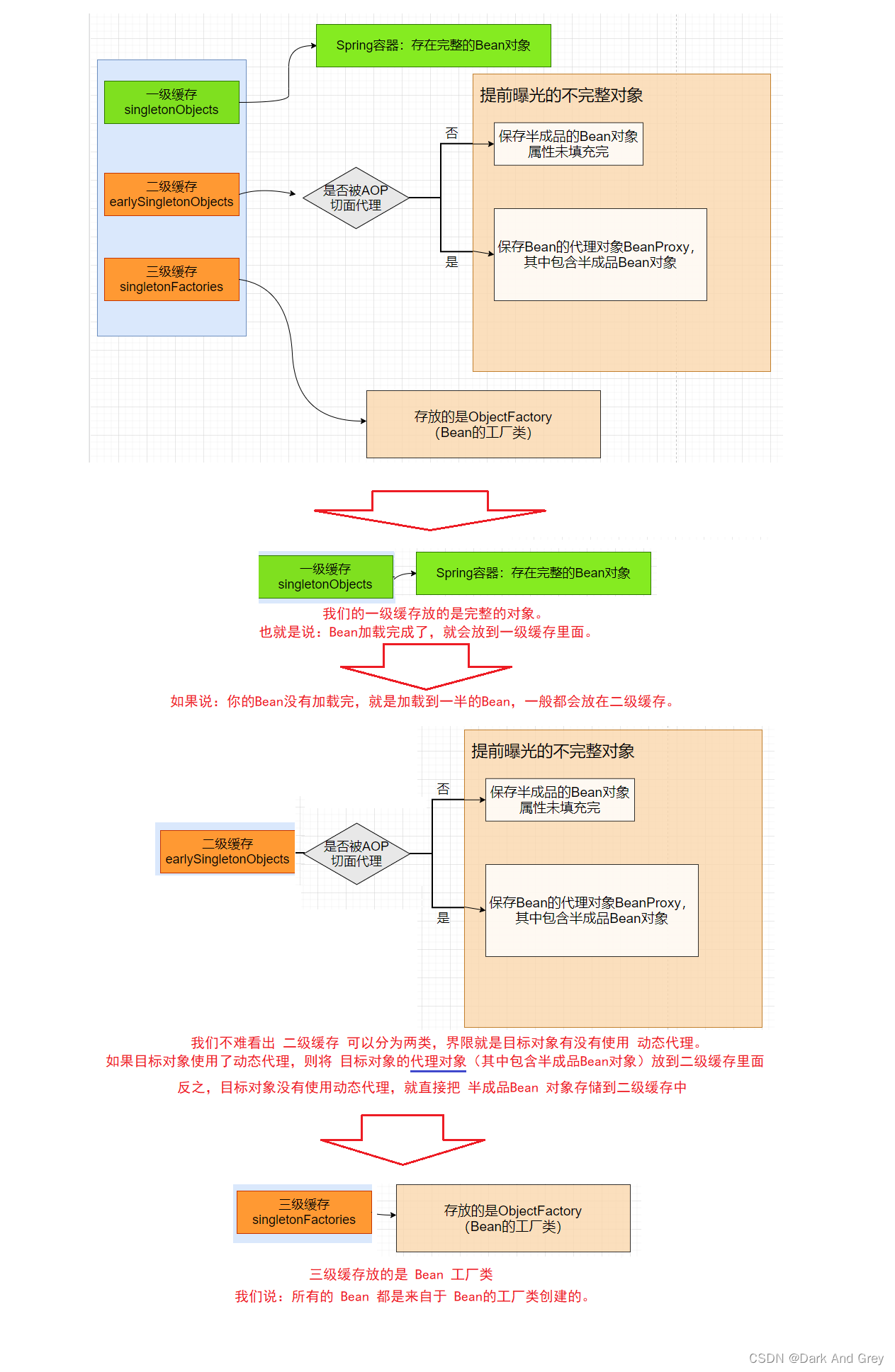

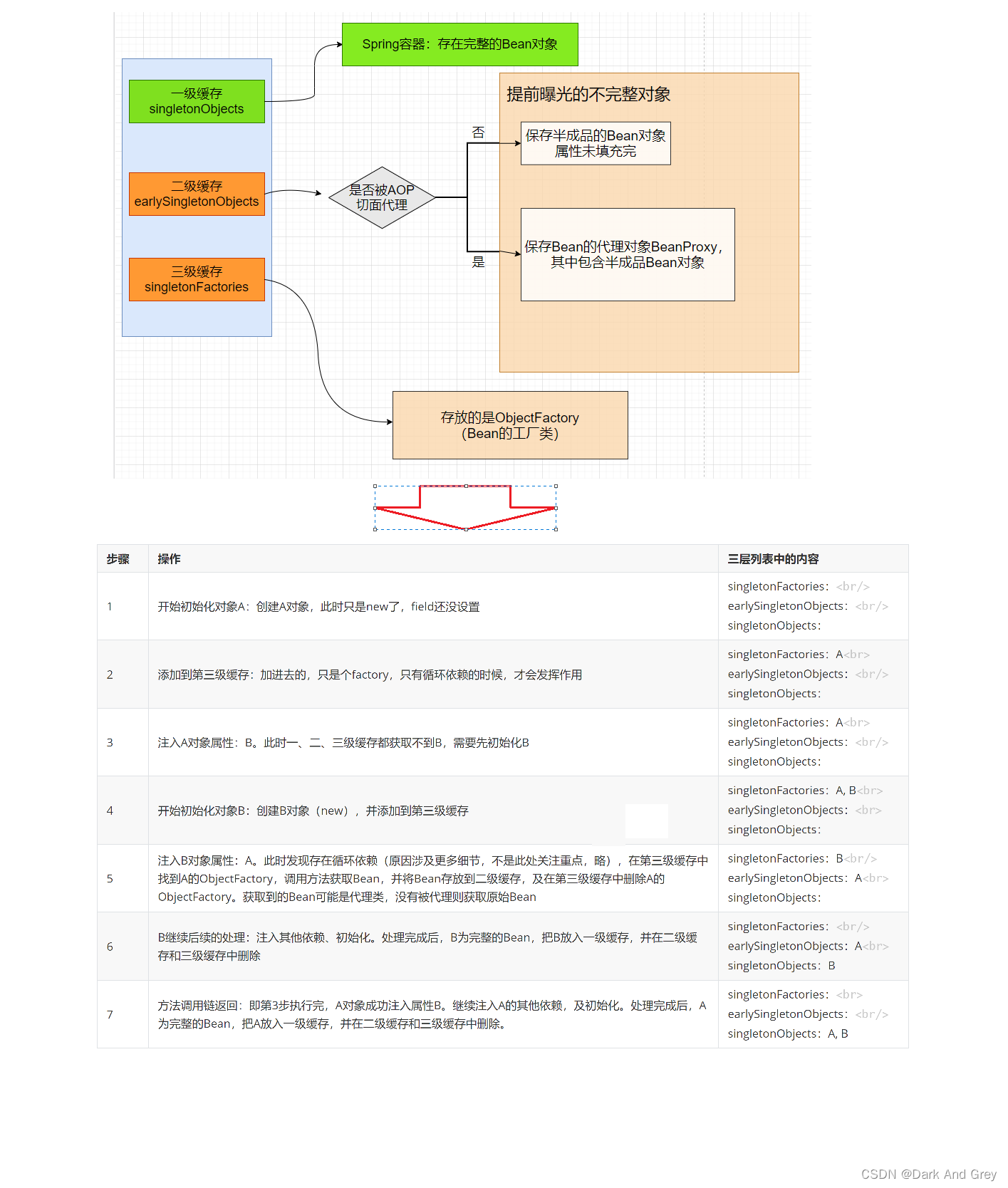
为什么要使⽤三级缓存
这个,在上一个标题底下,已经讲过了,你就当复习。
依照以上三级缓存的流程,其实使⽤⼆级缓存也能满⾜循环依赖的注⼊:普通的IoC容器使⽤⼀级缓存即可,但⽆法解决循环依赖问题。
解决循环依赖问题:使⽤⼆级缓存即可。
⼀级缓存保存完整Bean,⼆级缓存保存提前曝光的不完整的Bean。
需要AOP代理Bean时,有两种实现思路:
(1)再加⼀级缓存
(2)只使⽤⼆级缓存,其中⼆级缓存保存Bean的代理对象,代理对象中引⽤不完整的原始对象即可。(没有涉及到 AOP)
Spring使⽤三级缓存保存ObjectFactory即Bean⼯⼚,在代码的层次设计及扩展性上都会更好。
ps:ObjectFactory内部可以根据 SmartInstantiationAwareBeanPostProcessor 这样的后置处理器获取提前曝光的对象。
9.AOP的理解
AOP(Aspect-Oriented Programming):⾯向切⾯编程。
对多个业务代码横切来实现统⼀的业务管理,⽽不⽤侵⼊业务代码本身。这样⾯向切⾯的编程思想就是AOP。
使⽤场景:
⽇志记录,事务管理,性能统计,安全控制,异常处理等
优点:
代码解耦,统⼀业务功能对具体业务⽆侵⼊性,这样可扩展性更好,灵活性更⾼
SpringAOP是采取 动态代理 的⽅式,具体是基于JDK和CGLIB两种:
JDK动态代理:
需要被代理类实现接⼝,使⽤ InvocationHandler 和 Proxy 动态的⽣成代理类
CGLIB动态代理:
需要被代理类能被继承,不能被final修饰。使⽤ MethodInterceptor 来对⽅法拦截。CGLIB底层是基于ASM字节码框架,在运⾏时动态⽣成代理类SpringAOP如何使⽤:
@Aspect定义切⾯,并注册到容器中,
使⽤@Pointcut定义好切点⽅法后,可以对⽬标⽅法进⾏拦截:
前置通知
使⽤@Before:通知⽅法会在⽬标⽅法调⽤之前执⾏。
后置通知
使⽤@After:通知⽅法会在⽬标⽅法返回或者抛出异常后调⽤。
返回之后通知
使⽤@AfterReturning:通知⽅法会在⽬标⽅法返回后调⽤。
抛异常后通知
使⽤@AfterThrowing:通知⽅法会在⽬标⽅法抛出异常后调⽤。
环绕通知
使⽤@Around:通知包裹了被通知的⽅法,在被通知的⽅法通知之前和调⽤之后执⾏⾃定义的⾏为。
10.Spring事务中的隔离级别有哪⼏种?
在TransactionDefinition接⼝中定义了五个表示隔离级别的常量:
ISOLATION_DEFAULT:使⽤后端数据库默认的隔离级别,Mysql默认采⽤的REPEATABLE_READ隔离级别;Oracle默认采⽤的READ_COMMITTED隔离级别。
ISOLATION_READ_UNCOMMITTED:
最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
ISOLATION_READ_COMMITTED:
允许读取并发事务已经提交的数据,可以阻⽌脏读,但是幻读或不可重复读仍有可能发⽣
ISOLATION_REPEATABLE_READ:
对同⼀字段的多次读取结果都是⼀致的,除⾮数据是被本身事务⾃⼰所修改,可以阻⽌脏读和不可重复读,但幻读仍有可能发⽣。
ISOLATION_SERIALIZABLE:
最⾼的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执⾏,这样事务之间就完全不可能产⽣⼲扰,也就是说,该级别可以防⽌脏读、不可重复读以及幻读。
但是这将严重影响程序的性能。通常情况下也不会⽤到该级别。
11.Spring事务中有哪⼏种事务传播⾏为?
在TransactionDefinition接⼝中定义了七个表示事务传播⾏为的常量。
⽀持当前事务的情况:
PROPAGATION_REQUIRED:如果当前存在事务,则加⼊该事务;如果当前没有事务,则创建⼀个新的事务。
PROPAGATION_SUPPORTS:
如果当前存在事务,则加⼊该事务;如果当前没有事务,则以⾮事务的⽅式继续运⾏。
PROPAGATION_MANDATORY:
如果当前存在事务,则加⼊该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)。
不⽀持当前事务的情况:
PROPAGATION_REQUIRES_NEW:创建⼀个新的事务,如果当前存在事务,则把当前事务挂起。
PROPAGATION_NOT_SUPPORTED:
以⾮事务⽅式运⾏,如果当前存在事务,则把当前事务挂起。PROPAGATION_NEVER:
以⾮事务⽅式运⾏,如果当前存在事务,则抛出异常。
其他情况:
PROPAGATION_NESTED:如果当前存在事务,则创建⼀个事务作为当前事务的嵌套事务来运⾏;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。
12.SpringMVC的流程
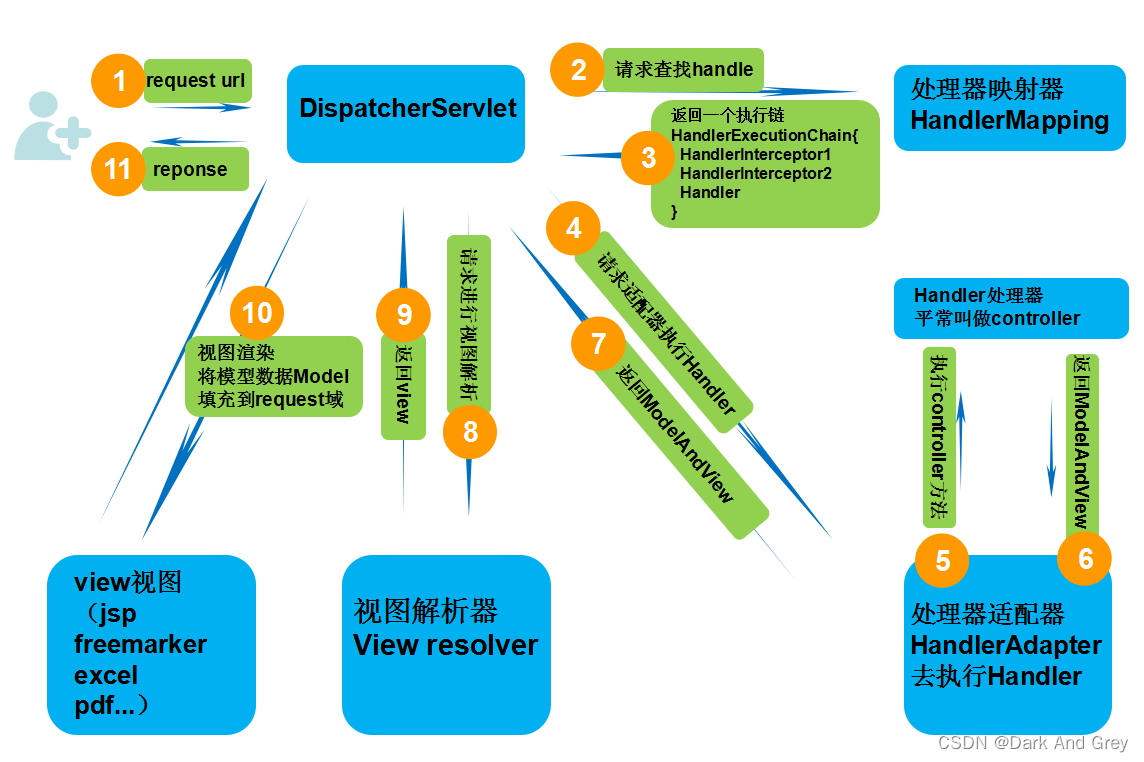
SpringMVC的请求响应步骤如下:
具体步骤:
第⼀步:(发起)发起请求到前端控制器(DispatcherServlet)
;第⼆步:
(查找)前端控制器请求HandlerMapping查找 Handler(可以根据xml配置、注解进⾏查找)
第三步:
(返回)处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会
把请求映射为HandlerExecutionChain对象(包含⼀个Handler处理器(⻚⾯控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略第四步:
(调⽤)前端控制器调⽤处理器适配器去执⾏Handler
第五步:
(执⾏)处理器适配器HandlerAdapter将会根据适配的结果去执⾏Handler
第六步:
(返回)Handler执⾏完成给适配器返回ModelAndView
第七步:
(接收)处理器适配器向前端控制器返回ModelAndView (ModelAndView是SpringMVC
框架的⼀个底层对象,包括 Model和view)第⼋步:
(解析)前端控制器请求视图解析器去进⾏视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
第九步:
(返回)视图解析器向前端控制器返回View
第⼗步:
(渲染)前端控制器进⾏视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充
到request域)第⼗⼀步:
(响应)前端控制器向⽤户响应结果
上述的执行流程,是返回一个静态页面。
还有一种执行模式,缺少 8 ~ 10 的步骤,返回的就是一个 普通的数据。
简单来说就是一个没有使用 @ResponseBody 或 @RestController 注解,项目默认返回的是一个静态页面,反之,使用了这两个注解之一,返回的就是一个普通的数据。
以下是对出现的⼀些组件的介绍:(1) 前端控制器DispatcherServlet(不需要程序员开发)。
作⽤:接收请求,响应结果,相当于转发器,中央处理器。有了DispatcherServlet减少了其它组件之间的耦合度。
(2) 处理器映射器HandlerMapping(不需要程序员开发)。
作⽤:根据请求的url查找Handler。
(3) 处理器适配器HandlerAdapter(不需要程序员开发)。
作⽤:按照特定规则(HandlerAdapter要求的规则)去执⾏Handler。
(4) 处理器Handler(需要程序员开发)。
注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执⾏Handler
(5) 视图解析器ViewResolver(不需要程序员开发)。
作⽤:进⾏视图解析,根据逻辑视图名解析成真正的视图(view)
(6) 视图View(需要程序员开发jsp)。
注意:View是⼀个接⼝,实现类⽀持不同的View类型(jsp、freemarker、pdf…)
ps:不需要程序员开发的,需要程序员⾃⼰做⼀下配置即可。
13.Mybatis中,#{}和${}的区别
#{变量名} 是预处理替换的⽅式,本质是 jdbc 中占位符的替换。
如传⼊字符串,会替换为带单引号的值。可以安全性更好.
$ {变量名} 是字符串的替换,只是对 sql 字符串进⾏拼接。如传⼊字符串,会直接替换为字符串的值,不加单引号。
#的⽅式可以很⼤程度的防⽌ sql 注⼊,相对来说更安全。⽽$的⽅式不能。
更多细节,点击标题跳转到对应的博文。
14.Mybatis中如何⼀对⼀、⼀对多关联
这个直接切过去看。
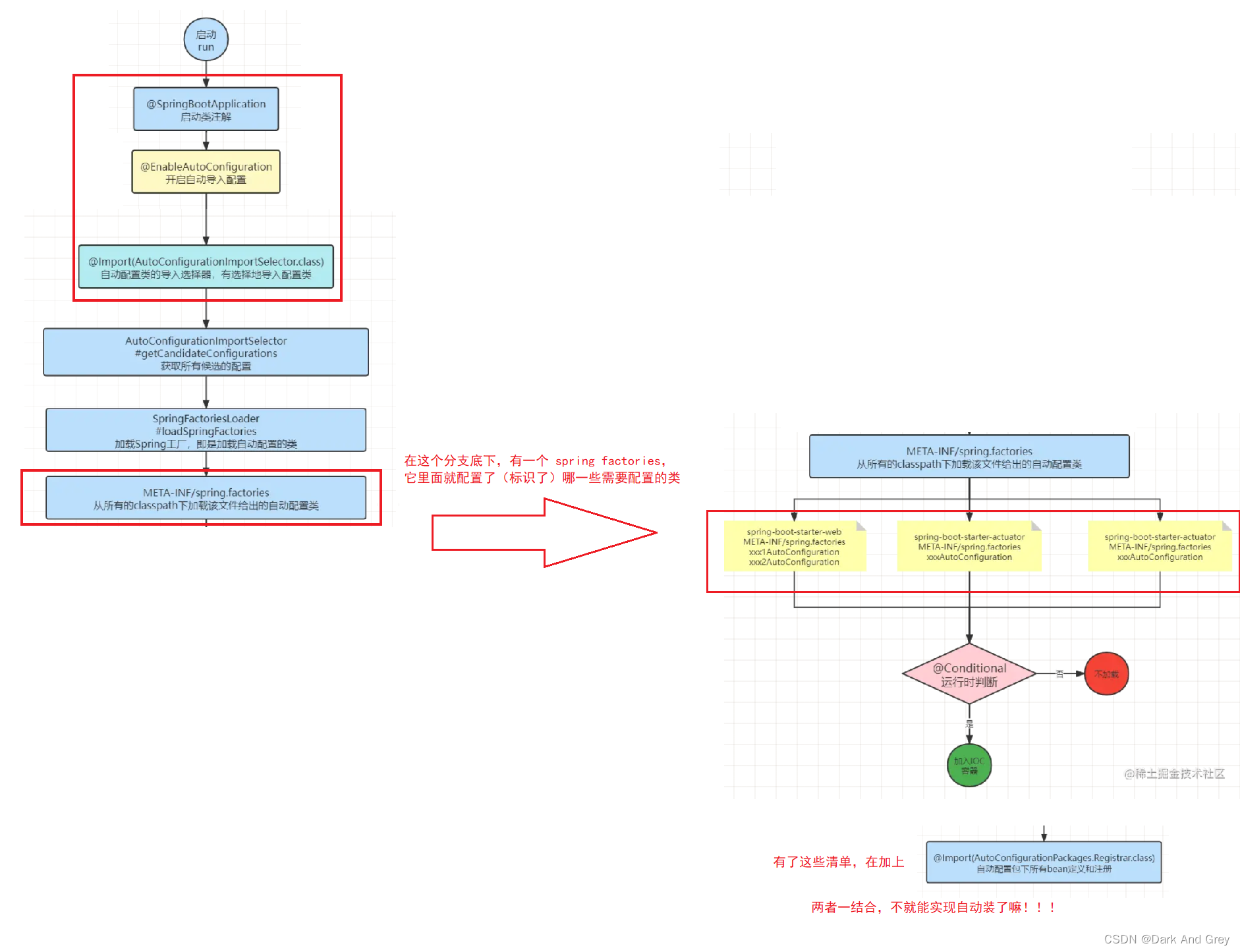
15.SpringBoot ⾃动配置原理
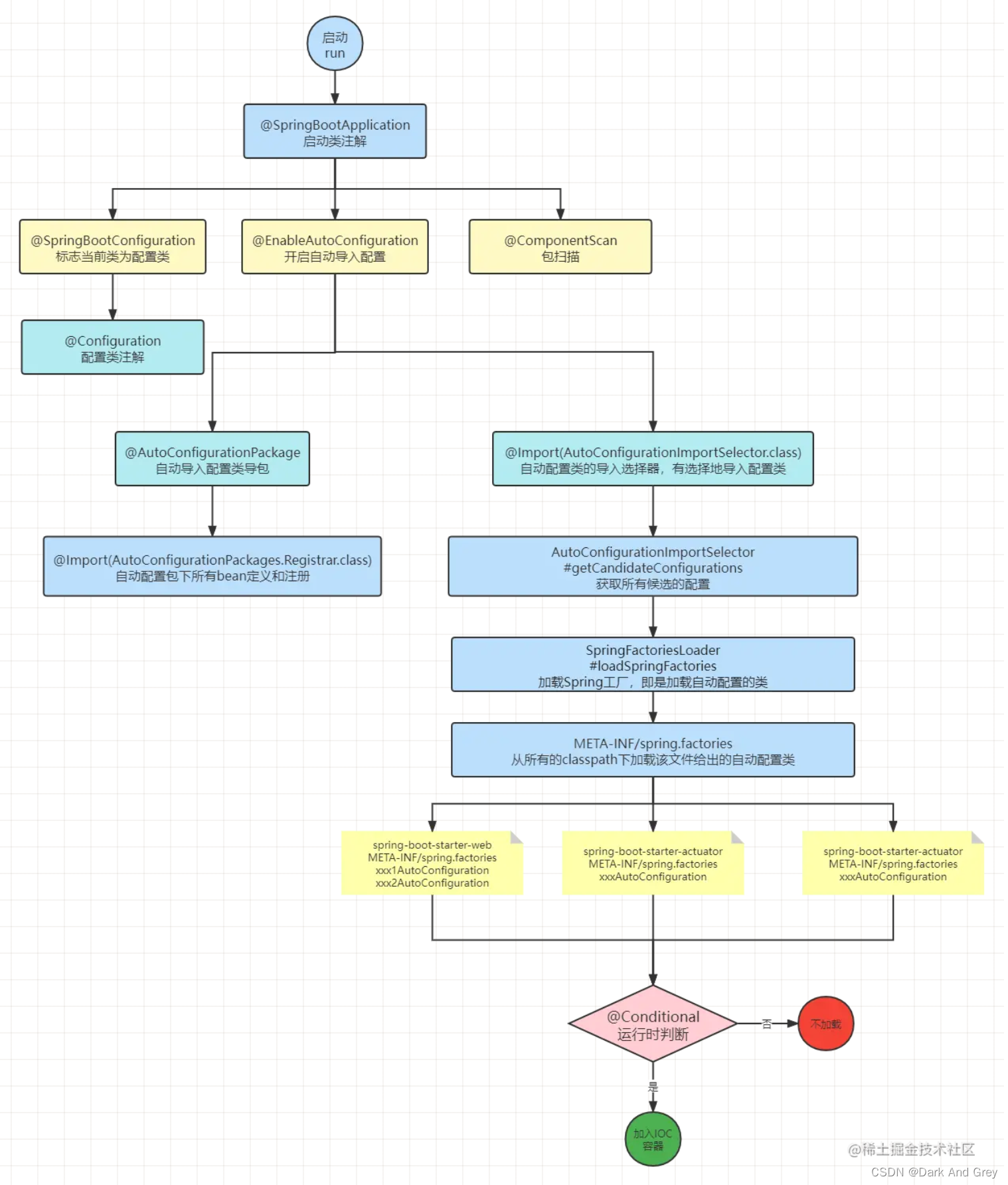
想要理解 SpringBoot ⾃动配置原理 ,只需要了解下面这个几个点:
1、SpringBoot 能够⾃动配置,主要就是因为 @SpringBootApplication 这个注解。
2、@SpringBootApplication 的分支 @EnableAutoConfiguration(开启自动导入配置),其里面有一个 @Import(AutoConfigurationPackages.Registrar,class)【自动配置包下所有的Bean定义和注册】注解,它会将需要自动装配的所有的Bean全部装配起来。
那好,问题来了:哪些类是需要自动装配呢?
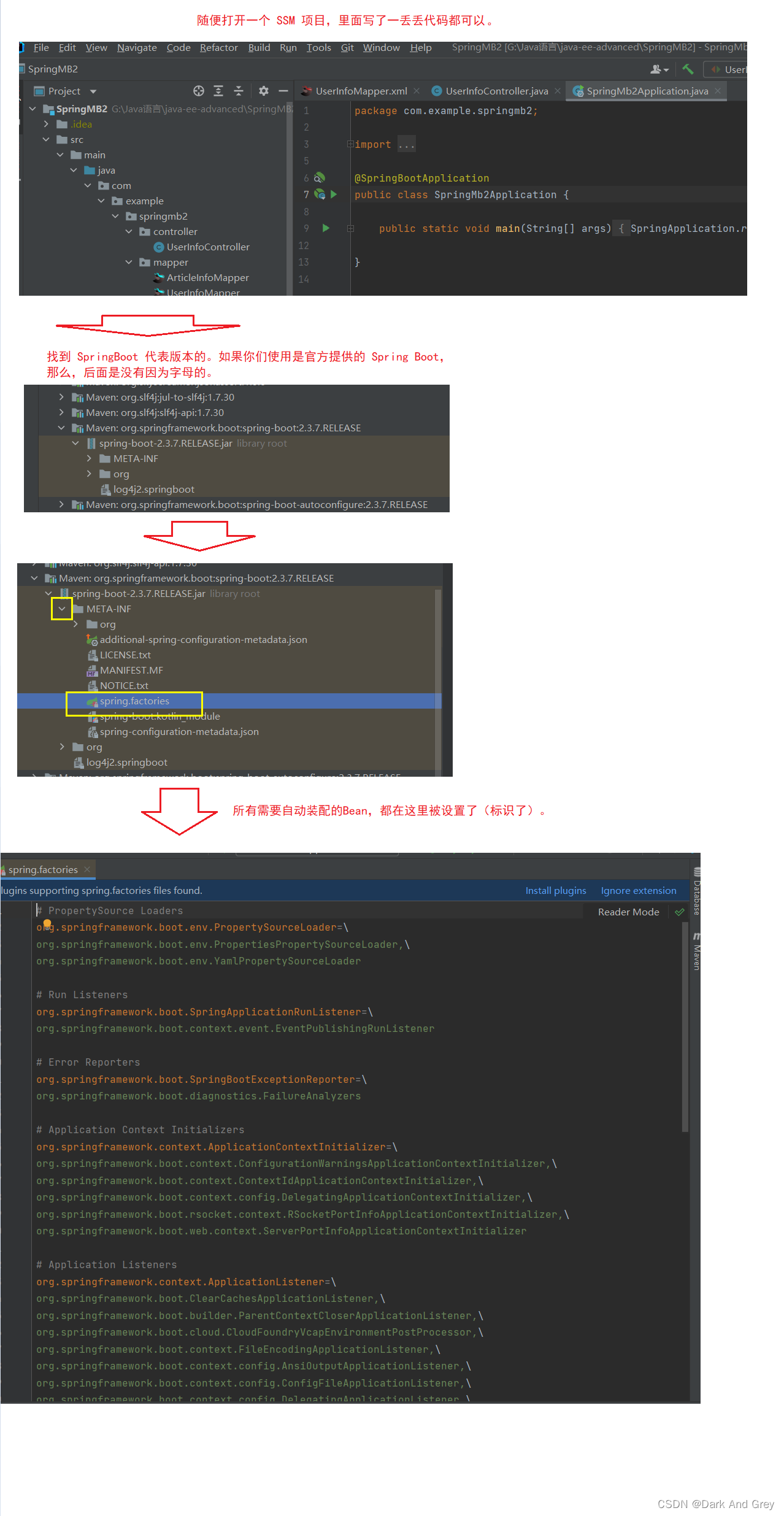
我可以帮你找一下标识所有需要自动装配Bean的文件位置在哪。
每一个 SSM 项目 都会有这个配置文件,不用担心找不到。
原文链接:https://blog.csdn.net/DarkAndGrey/article/details/126468052
所属网站分类: 技术文章 > 博客
作者:lovejava
链接:http://www.javaheidong.com/blog/article/504399/62093fa81bacdad6d0e4/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力