

Javase阶段面试题
发布于2020-11-19 20:33 阅读(1256) 评论(0) 点赞(8) 收藏(1)
1.浅谈八大基本数据类型
类型 字节 比特位 取值范围 包装类 byte 1 8 -128(-2 ^ 7) ~ 127(2 ^ 7 - 1)
Byte short 2 16 -32768(-2 ^ 15) ~ 32767(2 ^ 15 - 1)
Short int 4 32 (-2 ^ 31) ~ (2 ^ 31 - 1)
Integer long 8 64 (-2 ^ 63) ~ (2 ^ 63 - 1)
Long float 4 32 负数范围:-3.4028235E+38 ~ -1.4E-45
正数范围:1.4E-45 ~ 3.4028235E+38
Float double 8 64 负数范围:-1.7976931348623157E+308 ~ -4.9E-324
正数范围:4.9E-324 ~ 1.7976931348623157E+308
Double char
2 16 '\u0000' ~ '\uffff'(Unicode码) / 0 ~ 65535(ASCII码) Character boolean / / true / false Boolean
2.逻辑运算符
& 单与 两边都要计算
true & true = true true & false = false false & true = false false & false = false
| 单或 两边都要计算
true & true = true true | false = true false | true = true false & false = false
^ 异或
相同为0,不同为1
true ^ true = false true ^ false = true false ^ true = true false ^ false = false
! 非
&& 短路与 || 短路或
区分& 与 &&
相同点1:& 与 && 的运算结果相同
相同点2:当符号左边是true时,二者都会执行符号右边的运算。
不同点: 当符号左边是false时,&继续执行符号右边的运算,而&&不再执行符号右边的运算。区分:| 与 ||
相同点1:| 与 || 的运算结果相同
相同点2:当符号左边是false时,二者都会执行符号右边的运算。
不同点: 当符号左边是true时,| 继续执行符号右边的运算,而||不再执行符号右边的运算。
3.详谈Object类中的方法
- boolean equals(Object obj):指示其他某个对象是否与此对象"相等"。
equals()方法不能用来比较基本数据类型,只能比较引用数据类型。
Object类中equals()的定义:
public boolean equals(Object obj) {
return (this == obj);
}PS:Object类中定义的equals()方法和==的作用是相同的:都比较的是两个对象的地址值是否相同,即两个引用是否指向同一个对象实体。
像String、Date、File、包装类等都重写了Object类中的equals()方法。重写以后,比较的就不是两个引用的地址是否相同,而是比较两个对象的"实体内容"是否相同。
通常情况下,我们对于自定义的类,一般都会去重写它的equals()方法,从而来比较两个对象的"实体内容"是否相同。
- String toString():返回该对象的字符串表示。
当我们输出一个对象的引用时,实际上就是调用当前对象的toString()方法。
Object类中toString()的定义:
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
这打印的是当前这个对象的地址值。像String、Date、File、包装类等都重写了Object类中的toString()方法。重写以后,打印的就不是地址值,而是对象的具体实体内容。
对于自定义的类,一般也都会去重写它的toString()方法,用来返回对象的"实体内容"。
- Class<?> getClass():返回此Object的运行时类。
先来谈一下类的加载过程:程序经过javac.exe命令以后,会生成一个或多个字节码文件。接着我们使用java.exe命令对某个字节码文件进行解释运行。相当于将某个字节码文件加载到内存中。此过程就称为类的加载。加载到内存中的类,我们就称为运行时类,此运行时类,就作为Class类的一个实例。即Class的实例就对应着一个运行时类。加载到内存中的运行时类,会缓存一定的时间。在此时间之内,我们可以通过不同的方式来获取此运行时类。getClass()就是其中的一种方式。
顺便在这里说一下获取运行时类的四种方式:
- //方式一:调用运行时类的属性:.class
- Class clazz1 = 当前类.class;
- System.out.println(clazz1);
-
- //方式二:通过运行时类的对象,调用getClass()
- 当前类 p1 = new 当前类();
- Class clazz2 = p1.getClass();
- System.out.println(clazz2);
-
- //方式三:调用Class的静态方法:forName(String classPath)
- Class clazz3 = Class.forName("com.self.java.当前类");
- System.out.println(clazz3);
-
- //方式四:使用类的加载器:ClassLoader
- ClassLoader classLoader = 当前类.class.getClassLoader();
- Class clazz4 = classLoader.loadClass("com.self.java.当前类");
- System.out.println(clazz4);
- protected void finalize():当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
- void wait():在其他线程调用此对象的notify()方法或notifyAll()方法前,导致当前线程等待。
- void wait(long timeout):在其他线程调用此对象的notify()方法或notifyAll()方法,或者超过指定的时间量前,导致当前线程等待。
- void wait(long timeout,int nanos):在其他线程调用此对象的notify()方法或notifyAll()方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量前,导致当前线程等待。
这三个wait()方法构成了重载,但是用法基本是一样的。一旦执行wait()方法,当前线程就进入阻塞状态,并随之释放同步监视器。
- void notify():唤醒在此对象监视器上等待的单个线程。
执行此方法,就会唤醒被阻塞的一个线程。如果有多个线程被阻塞,就唤醒优先级高的那个。
- void notifyAll():唤醒在此对象监视器上等待的所有线程。
执行此方法,就会唤醒所有被阻塞的线程。
- int hashcode():返回该对象的哈希值。
hashCode()方法在某种程度上提高了equals()的比较效率。比如一个set集合中有10000个字符串,如果没有hashCode()方法,每次add()一个元素都调用equals()方法进行一个一个的比较的话,效率太低。但是有了hashCode方法之后,会先比较它们的哈希值是否相等,如果相等,再利用equals()方法来进行比较,不相等的话,就省去用equals()来进行比较这一步了。
问题:为什么重写了equals()方法之后还要再重写hashcode()方法?
针对这个问题,我们从两个方面来说:
- 第一个是效率
如上面所说,比如我们要往set集合中添加数据,因为set是不能存储重复元素的,所以我们每次添加新元素前都要先判断这个元素在不在集合里面。如果不重写hashCode()方法,每次add()一个元素都要调用equals()方法一个一个进行比较,这样效率太低。但是重写了hashCode方法之后,就可以先比较它们的哈希码值是否相等,如果相等,再利用equals()方法来进行比较,不相等的话,就省去用equals()来进行比较这一步了,能节省很多时间。
2. 保证是同一个对象
如果重写了equals()方法,而没有重写hashcode()方法,就会出现用equals()比较相等、但是哈希值不相等的对象,重写hashcode()方法就是为了避免这种情况的出现。
PS:如果两个对象相同,那么它们的hashCode值一定相同;反之如果两个对象的哈希值相同,它们不一定相同。
- protected Object clone():创建并返回此对象的一个副本。
提到clone()方法,这里就要谈一下深拷贝和浅拷贝。
浅拷贝:使用clone()方法来实现。
- 对于基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。
- 对于引用数据类型的成员变量,浅拷贝会进行引用传递,也就是将该成员变量的在内存当中的地址复制一份给新的对象。
这种情况下,修改一个对象中的成员变量,也会影响到另一个对象的该成员变量值 。
深拷贝:有两种实现方式,一是重写clone()方法来实现深拷贝,二是通过对象序列化实现深拷贝。
- 对于基本数据类型的成员变量,深拷贝会复制该对象的所有基本数据类型的成员变量值给新的对象。
- 对于引用数据类型的成员变量,深拷贝会为所有引用数据类型的成员变量申请存储空间,并复制每个引用数据类型成员变量所引用的对象,直到该对象可达的所有对象。也就是说,对象进行深拷贝要对整个对象(包括对象的引用类型)进行拷贝。
关于深拷贝和浅拷贝有个例子
- package com.self.sa.copy.deep;
-
- import java.io.Serializable;
- import java.util.Objects;
-
- public class DeepCloneableTarget implements Serializable, Cloneable {
-
- private static final long serialVersionUID = 1L;
- private String cloneName;
- private String cloneClass;
-
- public DeepCloneableTarget(String cloneName, String cloneClass) {
- this.cloneName = cloneName;
- this.cloneClass = cloneClass;
- }
-
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- @Override
- public boolean equals(Object o) {
- if (this == o) return true;
- if (o == null || getClass() != o.getClass()) return false;
- DeepCloneableTarget that = (DeepCloneableTarget) o;
- return Objects.equals(cloneName, that.cloneName) &&
- Objects.equals(cloneClass, that.cloneClass);
- }
-
- @Override
- public int hashCode() {
- return Objects.hash(cloneName, cloneClass);
- }
- }
- package com.self.sa.copy.deep;
-
- import java.io.*;
- import java.util.Objects;
-
- public class DeepProtoType implements Serializable, Cloneable {
-
- public String name; //String 属性
- public DeepCloneableTarget deepCloneableTarget; //引用类型
-
- public DeepProtoType() {}
-
- //深拷贝-方式1 使用clone()方法
- @Override
- protected Object clone() throws CloneNotSupportedException {
- Object deep = null;
- //这里完成对基本数据类型属性和String的克隆
- deep = super.clone();
- //对引用类型的属性进行单独处理
- DeepProtoType deepProtoType = (DeepProtoType) deep;
- deepProtoType.deepCloneableTarget = (DeepCloneableTarget) deepCloneableTarget.clone();
- return deepProtoType;
- }
-
- //深拷贝-方式2 通过对象的序列化实现(推荐)
- public Object deepClone() {
- //创建流对象
- ByteArrayOutputStream bos = null;
- ObjectOutputStream oos = null;
- ByteArrayInputStream bis = null;
- ObjectInputStream ois = null;
- try {
- //序列化
- bos = new ByteArrayOutputStream();
- //把字节流转为对象流
- oos = new ObjectOutputStream(bos);
- oos.writeObject(this); //当前这个对象以对象流的方式输出
- //反序列化
- bis = new ByteArrayInputStream(bos.toByteArray());
- ois = new ObjectInputStream(bis);
- DeepProtoType copy = (DeepProtoType) ois.readObject();
- return copy;
- } catch (Exception e) {
- e.printStackTrace();
- return null;
- } finally {
- try {
- bos.close();
- oos.close();
- bis.close();
- ois.close();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
-
- @Override
- public boolean equals(Object o) {
- if (this == o) return true;
- if (o == null || getClass() != o.getClass()) return false;
- DeepProtoType that = (DeepProtoType) o;
- return Objects.equals(name, that.name) &&
- Objects.equals(deepCloneableTarget, that.deepCloneableTarget);
- }
-
- @Override
- public int hashCode() {
- return Objects.hash(name, deepCloneableTarget);
- }
-
- }
- package com.self.sa.copy.deep;
-
- public class Client {
- public static void main(String[] args) throws CloneNotSupportedException {
-
- DeepProtoType p = new DeepProtoType();
- p.name = "哈哈";
- p.deepCloneableTarget = new DeepCloneableTarget("大牛", "牛大");
-
- //方式1 完成深拷贝
- DeepProtoType p1 = (DeepProtoType) p.clone();
- System.out.println(p.deepCloneableTarget == p1.deepCloneableTarget);//false
- System.out.println(p.equals(p1));//true
-
- //方式2 完成深拷贝
- DeepProtoType p2 = (DeepProtoType) p.deepClone();
- System.out.println(p.deepCloneableTarget.hashCode() == p2.deepCloneableTarget.hashCode());//true
- System.out.println(p == p2);//true
- System.out.println(p.equals(p2));//true
- }
- }
4.基本数据类型、包装类、String之间的相互转换
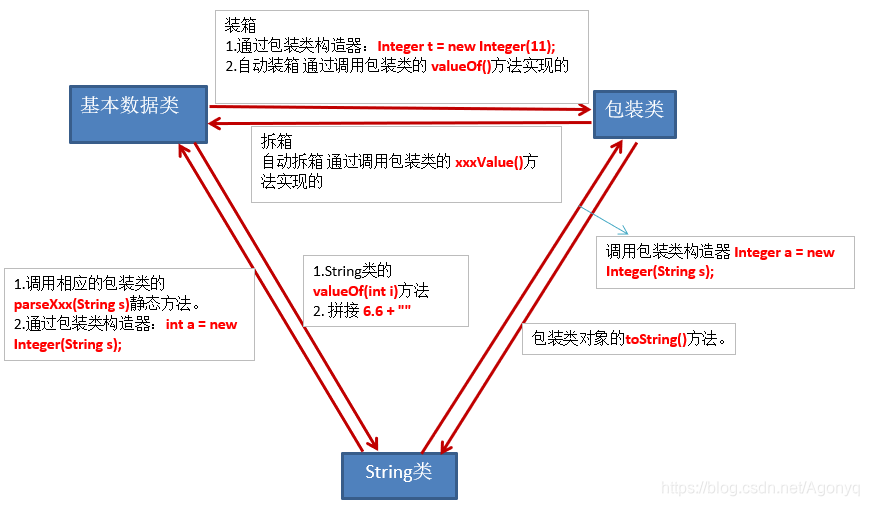
PS:关于Integer再说一下:
Integer的范围是-128 ~ 127,超出这个范围就会重新创建对象。
5.值传递和引用传递
首先说一下,Java参数传递机制只有值传递,没有引用传递。
- 如果参数是基本数据类型,此时实参赋给形参的是实参真实存储的数据值。
- 如果参数是引用数据类型,此时实参赋给形参的是实参存储数据的地址值。
推广一下:
- 如果变量是基本数据类型,此时赋值的是变量所保存的数据值。
- 如果变量是引用数据类型,此时赋值的是变量所保存的数据的地址值。
顺便再提一下引用传递,引用传递是针对对象而言,传递的是地址,修改地址会改变原对象。但是对于String类型,是值传递,因为String不可变。
6.String为什么被设计为不可变?String不可变体现在哪里?
一、首先,关于String类我们知道,String底层使用了char型数组,而且被final修饰,所以不可变。
不可变总的来说有以下几个原因:
(1)便于实现字符串常量池
在Java中,我们会经常大量的使用String常量,如果每声明一个String都创建一个String对象,将会造成极大的空间资源的浪费。所以Java提出了字符串常量池的概念,在堆中开辟一块存储空间表示字符串常量池,当我们初始化一个String变量时,如果该字符串已经存在了,会直接拿到该字符串的引用,而不会去创建一个新的字符串常量。如果String是可变的,那么当某一个字符串变量改变它的值,其在字符串常量池的值也会发生改变,这样字符串常量池将不能够实现!
(2)加快字符串的处理速度
由于String是不可变的,这样就保证了每个字符串hashcode的唯一性。当我们在创建String对象时,其hashcode就已经确定了,被缓存下来,就不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象,所以HashMap中的键往往都使用String。
(3)保证了安全性
在并发场景下,多个线程同时读一个资源,是安全的,不会引发竞争;但当多个线程对资源进行写操作的时候却是不安全的,由于String设计为不可变,所以保证了多线程的安全。
二、String不可变主要体现在以下几个方面:
(1)当对字符串重新赋值时,
(2)当对字符串进行拼接时,
(3)当用replace()方法修改指定位置的字符串时,
(1)、(2)、(3)三种情况的处理方法都是一样的,都会在堆当中重新开辟内存空间,然后从字符串常量池拿到新的值的地址给原对象,而不是在原字符串上进行修改。
关于字符串常量池这里再提一些内容:
(1)jdk 1.6及以前:字符串常量池存储在方法区(永久区),到jdk 1.7及之后:字符串常量池存储在堆空间。
(2)字符串常量池不会存储相同内容的字符串,它底层使用Hashtable(数组+链表) ;
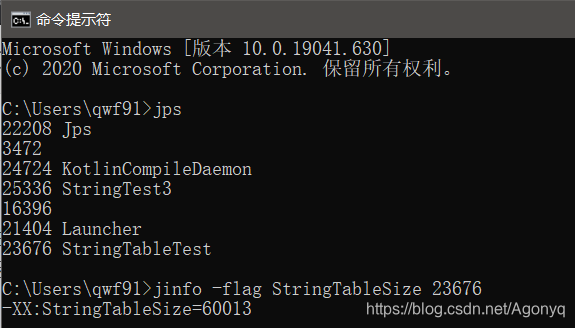
(3)并且容量是60013。途径是:运行下面代码,然后在命令行输入jps,再输入jinfo -flag StringTableSize+进程id,就可以看到字符串常量池的容量。
效果如下图:
7.String、StringBuffer、StringBuilder三者异同
String:不可变的字符序列;底层使用char[ ]存储。
StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[ ]存储,默认容量为16。
StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[ ]存储,默认容量为16。关于扩容问题:如果要添加的数据过多,底层数组盛不下了,那就需要扩容底层的数组。 默认情况下,扩容的长度为原来容量的2倍 + 2,同时将原数组中的元素复制到新的数组中。
String、StringBuffer、StringBuilder三者的执行效率:从高到低排列为StringBuilder > StringBuffer > String。所以开发中一般建议用StringBuilder。
8.关于字符串的拼接问题
(1)常量与常量的拼接结果在常量池,这是因为存在编译期优化。所谓编译期优化就是指如果两个字符串都是常量,并进行拼接的话,在编译的时候会自动将它们进行拼接。
(2)只要有一个是变量,结果就在堆中,因为会在堆当中重新new String()对象。
(3)如果拼接的结果调用intern()方法,返回值就在常量池中。并且会主动将常量池中还没有的字符串常量放入池中,并返回此对象地址。
详细看以下代码,代码注释当中都有详细说明
所属网站分类: 技术文章 > 博客
作者:java小王子
链接:http://www.javaheidong.com/blog/article/994/490380ce4f926bb48622/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力