

Java 程序执行流程
发布于2021-06-12 14:30 阅读(391) 评论(0) 点赞(27) 收藏(1)
一、Java 程序执行流程
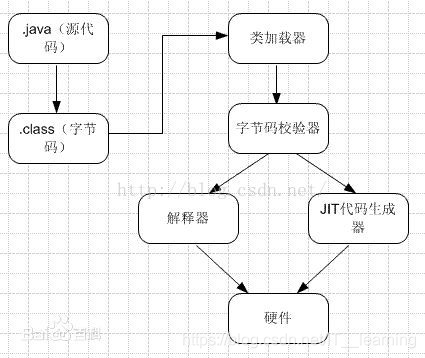
1、源文件由编译器编译成字节码(ByteCode)
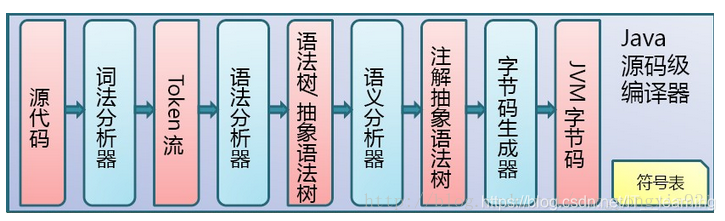
Java 源代码编译成 .class 字节码文件,是 Java 的第一次编译。生成的这个 .class 文件就是可以到处运行的文件。
2、.Class 字节码文件转换成目标机器代码,由JVM执行引擎来完成
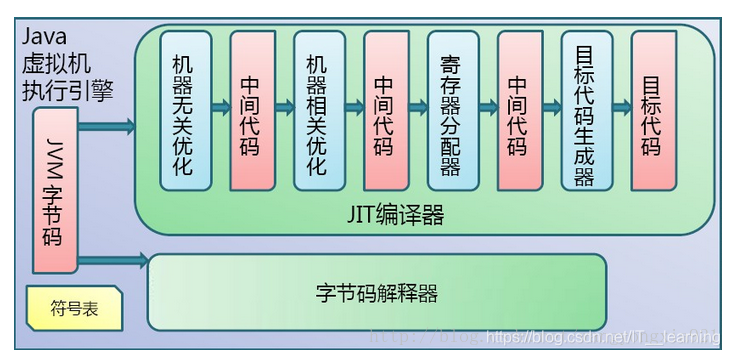
字节码无法直接交给硬件执行,需要虚拟机翻译成机器码才能执行。“翻译”的策略有两种:解释执行和编译执行(又称即使编译(JIT))。解释执行是每执行一条字节码的时候把字节码翻译成机器码并执行,优点是启动效率快,缺点是整体的执行速度较慢。编译执行预先把热点代码的所有字节码编译成机器码然后一起执行,其特点与解释执行相反,启动较慢执行较快。
(1)JVM 相关参数

(2)解释执行与即时编译的比较
● 解释执行: 通过解释器,在代码执行时逐条翻译成机器码,
不做保存。
● 即时编译(JIT): 将热点代码编译成与本地平台相关的机器码,并保存到内存,因为要反复执行。
时间开销
解释器的执行,抽象的看: 输入的代码 -> [ 解释器 解释执行 ] -> 执行结果
JIT编译的执行,抽象的看: 输入的代码 -> [ 编译器 编译 ] -> 编译后的代码 -> [ 执行 ] -> 执行结果
说 JIT 比解释快,其实说的是“执行编译后的代码”比“解释器解释执行”要快,并不是说“编译”这个动作比“解释”这个动作快。
JIT编译再怎么快,至少也比解释执行一次略慢一些,而要得到最后的执行结果还得再经过一个“执行编译后的代码”的过程。
所以,对“只执行一次”的代码而言,解释执行其实总是比JIT编译执行要快。
怎么算是“只执行一次的代码”呢?粗略说,下面两个条件同时满足时就是严格的“只执行一次” 1、只被调用一次,例如类的构造器(class initializer,()) 2、没有循环 对只执行一次的代码做JIT编译再执行,可以说是得不偿失。
对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。
只有对频繁执行的代码,JIT编译才能保证有正面的收益。
空间开销
对一般的 Java 方法而言,编译后代码的大小相对于字节码的大小,膨胀比达到10倍是很正常的。同上面说的时间开销一样,这里的空间开销也是,只有对执行频繁的代码才值得编译,如果把所有代码都编译则会显著增加代码所占空间,导致“代码爆炸”。
这也就解释了为什么有些JVM会选择不总是做JIT编译,而是选择用解释器+JIT编译器的混合执行引擎。
二、Java 程序执行的细节
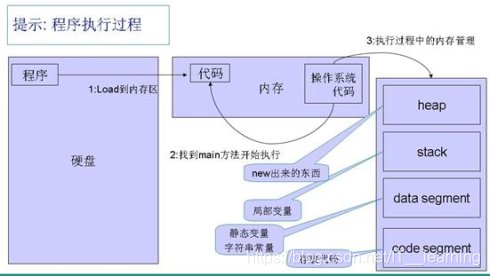
Java 程序执行过程中的内存分配情况:
示例程序:
//MainApp.java
public class MainApp {
public static void main(String[] args) {
Animal animal = new Animal("Puppy");
animal.printName();
}
}
//Animal.java
public class Animal {
public String name;
public Animal(String name) {
this.name = name;
}
public void printName() {
System.out.println("Animal ["+name+"]");
}
}
1、编译
创建完源文件之后,程序会先被编译为 .class 文件。Java 编译一个类时,如果这个类所依赖的类还没有被编译,编译器就会先编译这个被依赖的类,然后引用,否则直接引用,这个有点象 make。如果Java 编译器在指定目录下找不到该类所其依赖的类的 .class 文件或者 .java 源文件的话,编译器话报“cant find symbol”的错误。
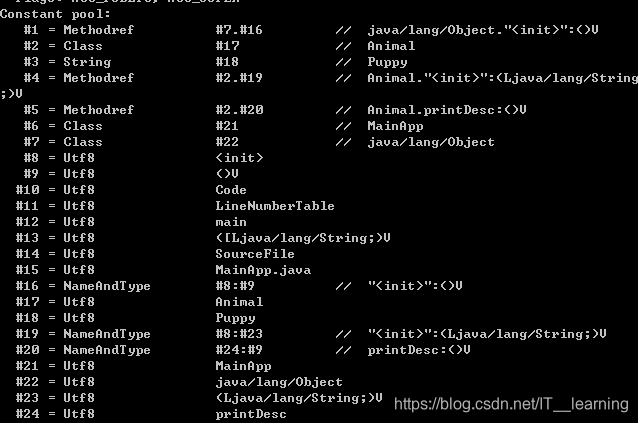
编译后的字节码文件格式主要分为两部分:常量池和方法字节码。
常量池记录的是代码出现过的所有token(类名,成员变量名等等)以及符号引用(方法引用,成员变量引用等等);方法字节码放的是类中各个方法的字节码。
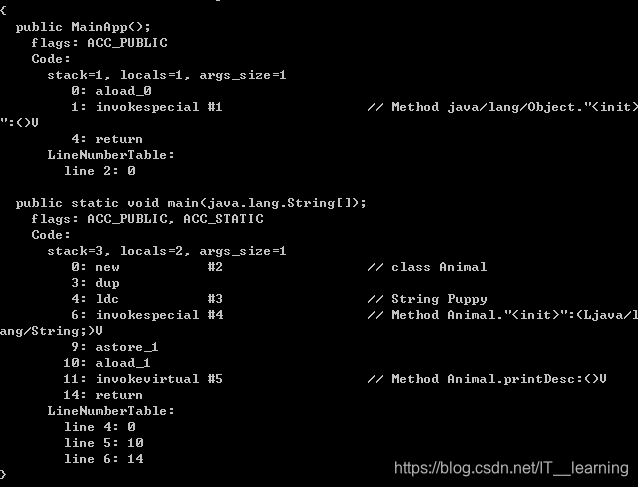
下面是MainApp.class通过反汇编的结果,我们可以清楚看到.class文件的结构:
MainApp类常量池
MainApp类方法字节码
2、JVM 运行
Java类运行的过程大概可分为两个过程:类的加载和类的执行。JVM 在程序第一次主动使用类的时候,才会去加载该类。也就是说,JVM 并不是在一开始就把一个程序就所有的类都加载到内存中,而是到不得不用的时候才把它加载进来,而且只加载一次。
程序运行的详细步骤:
①
启动 JVM 进程: 在命令行上敲 Java AppMain,对 Java 程序进行编译得到 MainApp.class 文件后,系统就会启动一个 JVM 进程;
②类加载:JVM 进程从 classpath 路径中找到一个名为 AppMain.class 的二进制文件,将 MainApp 的类信息加载到运行时数据区的方法区内,这个过程叫做 MainApp 类的加载。
③执行主函数,加载相关类:JVM 找到 AppMain 的主函数入口,开始执行 main 函数。 main 函数的第一条命令是 Animal animal = new Animal(“Puppy”); 就是让 JVM 创建一个 Animal 对象,但是这时候方法区中没有 Animal 类的信息,所以 JVM 马上加载 Animal 类,把 Animal 类的类型信息放到方法区中。于是JVM 以一个直接指向方法区 Animal类的指针替换了常量池中第一项的符号引用。
④分配内存,实例化对象:加载完 Animal 类之后,JVM 做的第一件事情就是在堆区中为一个新的 Animal 实例分配内存, 然后调用构造函数初始化 Animal 实例,这个 Animal 实例持有着指向方法区的 Animal 类的类型信息(其中包含有方法表,Java 动态绑定的底层实现)的引用。( animal 指向 Animal 实例对象的引用会自动的放在栈中,字符串常量 ”super_yc” 会自动的放在方法区的常量池中,实例对象会自动的放入堆区)。
⑤程序运行:当使用 animal.printName() 的时候,JVM 根据 animal 引用找到 Animal 对象,然后根据 Animal 对象持有的引用定位到方法区中 Animal 类的类型信息的方法表,获得 printName() 函数的字节码的地址,然后开始运行printName()函数。
注:Java 类中所有 public 和 protected 的实例方法都采用动态绑定机制,所有私有方法、静态方法、构造器及初始化方法 < clinit> 都是采用静态绑定机制。而使用动态绑定机制的时候会用到方法表,静态绑定时并不会用到。本文只是讲述 Java 程序运行的大概过程,所以并没有细加区分。
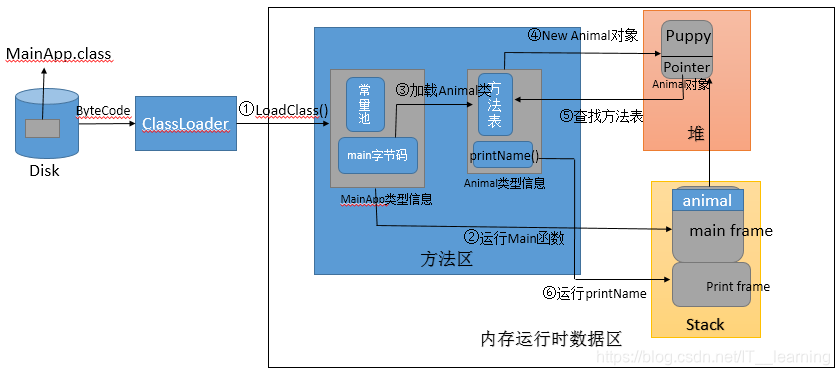
Java 程序创建对象的细节
示例代码
// AppMain.java
public class AppMain { //运行时, jvm 把appmain的代码全部都放入方法区
public static void main(String[] args) { //main 方法本身放入方法区。
Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
Sample test2 = new Sample( " 测试2 " );
test1.printName();
test2.printName();
}
}
// Sample.java
public class Sample { //运行时, jvm 把appmain的信息都放入方法区
/** 范例名称 */
private String name; //new Sample实例后, name 引用放入栈区里, name 对应的 String 对象放入
/** 构造方法 */
public Sample(String name)
{
this .name = name;
}
/** 输出 */
public void printName() //在没有对象的时候,print方法跟随sample类被放入方法区里。
{
System.out.println(name);
}
}
该程序的内存分布 图:
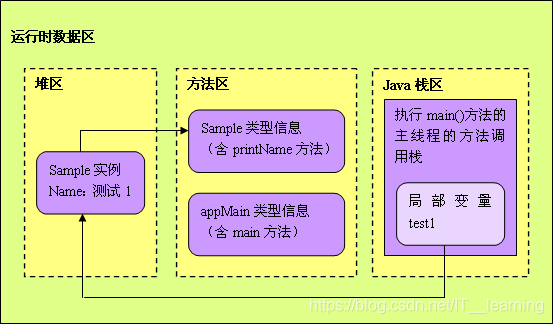
(1)运行该程序时,首先启动一个Java虚拟机进程,这个进程首先从 classpath 中找到 AppMain.class 文件,读取这个文件中的二进制数据,然后把 Appmain 类的类信息存放到运行时数据区的方法区中,这就是 AppMain 类的加载过程。
(2)Java虚拟机定位到方法区中AppMain类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
Sample test1=new Sample("测试1");
该语句的执行过程:
● JVM 到方法区找到 Sample 类的类型信息,没有找到,因为Sample类还没有加载到方法区(这里可以看出,
Java 中的类是单独存在的,而且刚开始的时候不会跟随包含类一起被加载,等到要用的时候才被加载)。Java虚拟机立马加载Sample类,把Sample类的类型信息存放在方法区里。
●JVM 首先在堆区中为一个新的 Sample 实例分配内存,并在 Sample 实例的内存中存放一个方法区中存放 Sample 类的类型信息的内存地址。
● JVM 的进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素就被称为栈帧,每当线程调用一个方法的时候就会向方法栈压入一个新帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。
● 位于 “=” 前的 Test1 是一个在 main() 方法中定义的一个变量(一个 Sample 对象的引用),它被会添加到执行 main() 方法的主线程的 Java 方法调用栈中,而 “=” 将把这个 test1 变量指向堆区中的 Sample 实例。
● JVM 在堆区里继续创建另一个 Sample 实例,并在 main() 方法的方法调用栈中添加一个 Test2 变量,该变量指向堆区中刚才创建的 Sample 新实例。
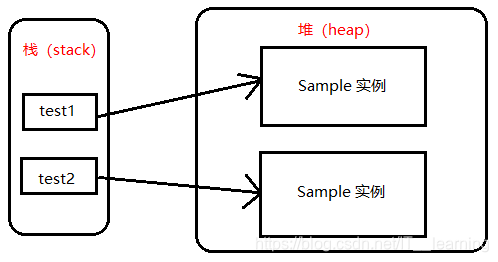
(3)创建完对象后,执行对象中的方法:
test1.printName();
该语句的执行过程:
● JVM 依次执行它们的 printName() 方法。
当 JVM 执行 test1.printName() 方法时,JVM 根据局部变量 test1 持有的引用,定位到堆区中的 Sample 实例,再根据 Sample 实例持有的引用,定位到方法区中 Sample 类的类型信息,从而获得 printName() 方法的字节码,接着执行 printName() 方法包含的指令,开始执行。
所属网站分类: 技术文章 > 博客
作者:飞翔公园
链接:http://www.javaheidong.com/blog/article/222196/ba94570248c0d8ec6058/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力